

Containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性。Containerd 可以在宿主机中管理完整的容器生命周期:
管理容器的生命周期(从创建容器到销毁容器)
拉取/推送容器镜像
存储管理(管理镜像及容器数据的存储)
调用 runC 运行容器(与 runC 等容器运行时交互)
管理容器网络接口
事实上,在早期,containerd一直作为docker的子组件而存在:
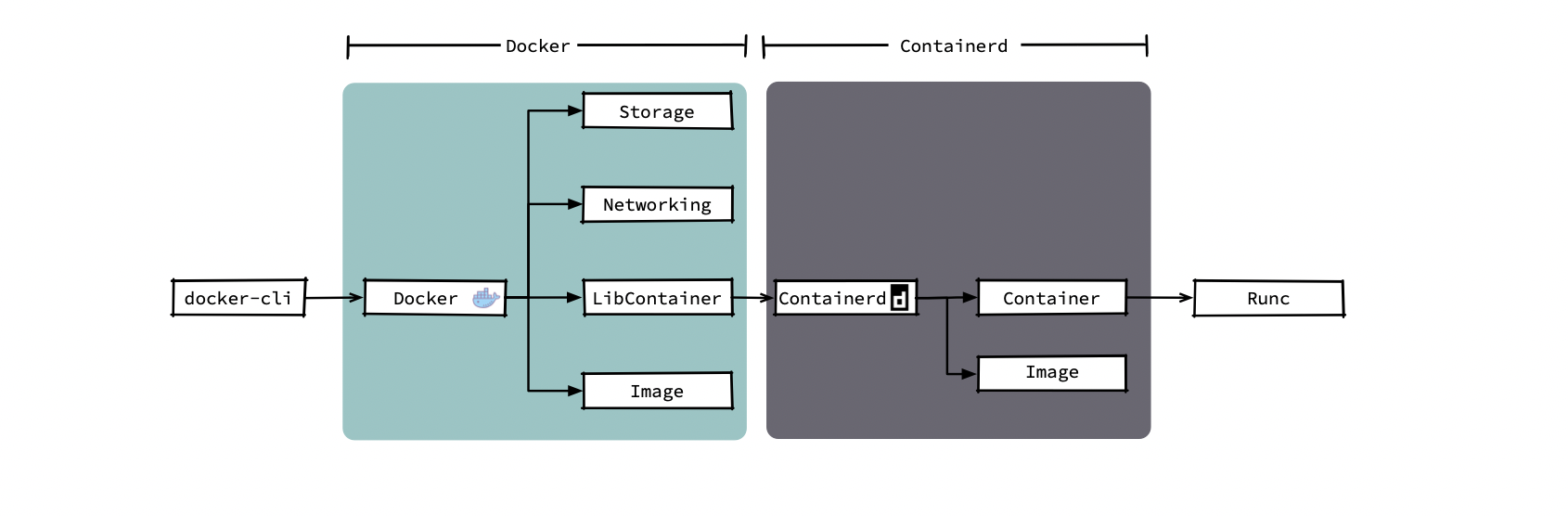
参考: https://www.cnblogs.com/tencent-cloud-native/p/14134164.html
一、容器原理
IT企业的软件开发模型由传统的客户端/服务端模型,变成浏览器/服务器模型;由物理机变成虚拟机,再变成IaaS(基础架构云)和PaaS(应用云)。通过近些年的云化,很多企业实现了基础架构资源(虚拟机、网络、存储和数据库等资源)的云化和池化,用户可以通过云化迅速的获取业务应用所需的机器、数据库以及数据存储。
当上层业务和下层基础架构资源完备后,中间的一个连接就应运而生——容器化,通过容器方案实现应用在基础架构资源上的“一键式”部署相对于传统部署拥有以下优势:
快速:原来的应用需要几天甚至十几天才能全部部署完毕,现在只需要一天甚至几个小时就可以部署完毕
便捷:原来的应用需要jar、war、rpm等方式部署,现在只需要镜像和容器化平台
低成本:应用成本、资源成本,以及人力成本的降低
虚拟机与容器的对比
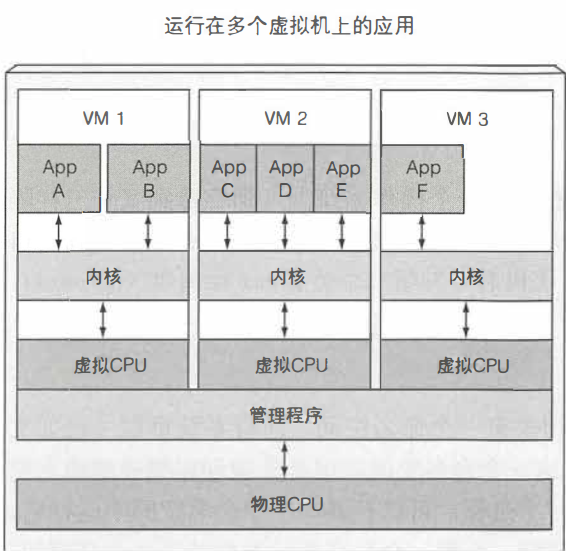
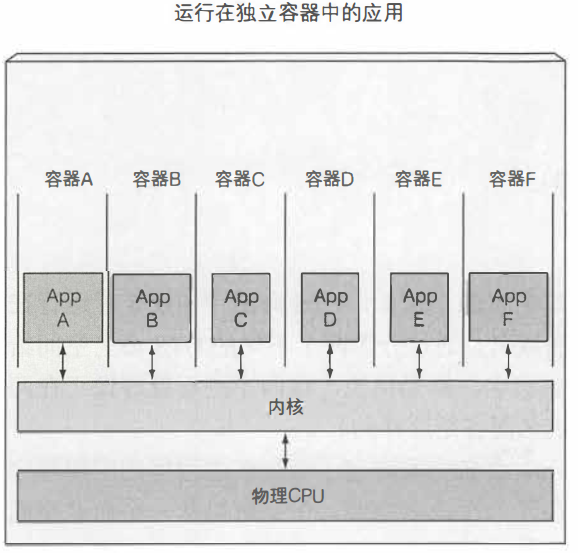
相比较而言,容器的优势:
轻量级:允许在相同的硬件上运行更多数量的组件。每个虚拟机需要运行自己的一组系统进程,进程是运行在不同的操作系统上的。而一个容器仅仅是运行在宿主机上被隔离的单个进程,仅消耗应用容器消耗的资源,不会有其他进程的开销。
低消耗:虚拟机提供完全隔离的环境,每个虚拟机运行在它自己的Linux内核上,容器是调用同一个内核。
容器的隔离机制
容器基于linux内核的两大特性namespace和cgroup分别实现进程的隔离以及资源限制。
Namespace
Linux命名空间使每个进程只看到自己的系统视图(文件、进程、网络接口、主机名等)
默认,每个Linux系统起始有一个命名空间,所有系统资源(如文件系统、用户ID、网络接口等)属于这个命名空间,但可以创建额外的命名空间,以及在它们之间组织资源,一个进程可以运行在其中一个命名空间中,该进程只能看到该命名空间下的资源。
命名空间用于隔离一组特定的资源,命名空间类型如下:
Mount(mnt)
Process ID(pid)
Network(net)
Inter-process communication(ipd)
UTS
User ID(user)
Cgroup
通过cgroups限制容器能使用的系统资源,cgroups是一个Linux内核功能,可以限制一个进程或者一组进程的资源使用,一个进程的资源(CPU、内存、网络带宽等)使用量不可以超过被分配的量。
二、Containerd的前世今生
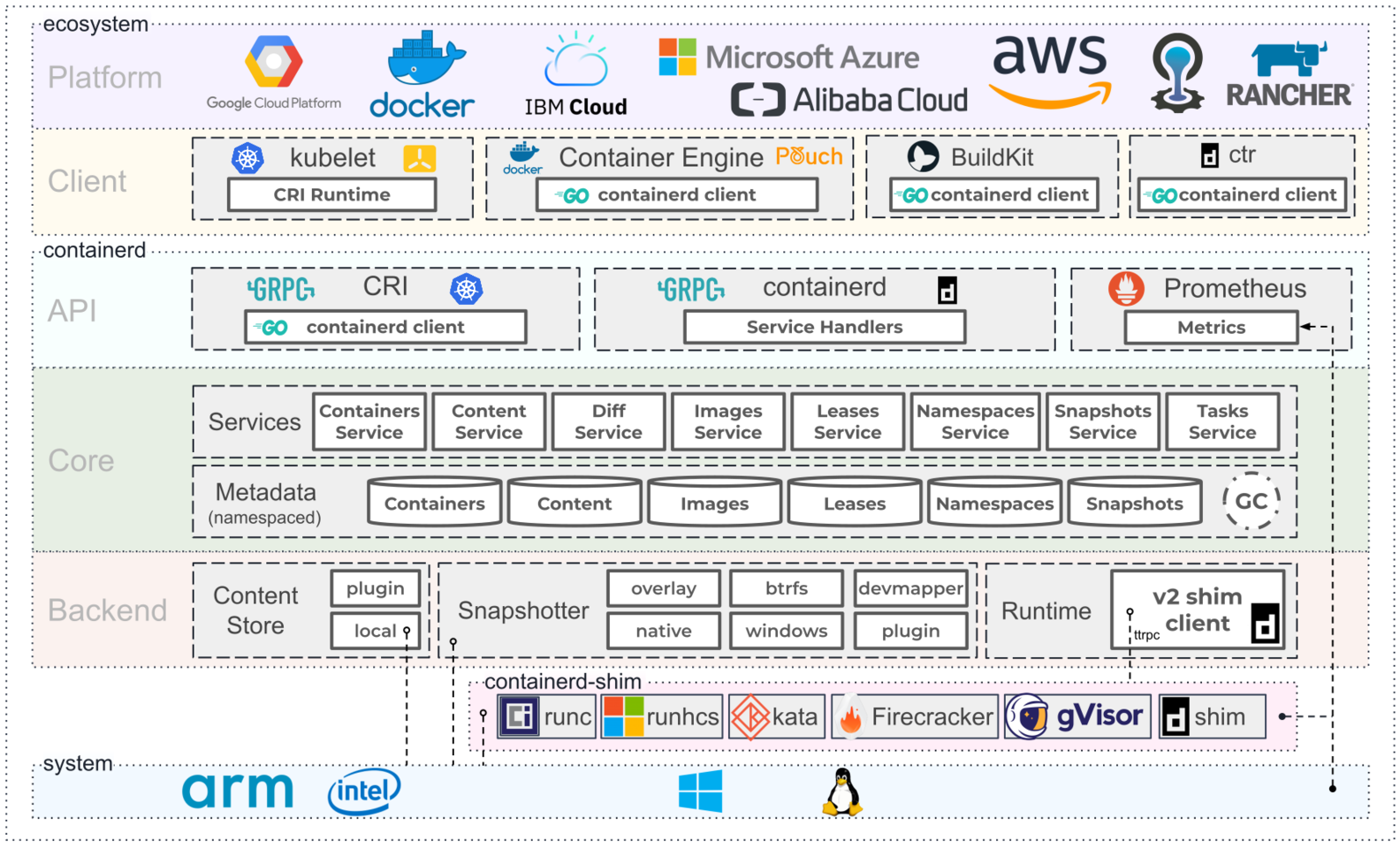
Containerd简介
containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性。其诞生于Docker,提供如下功能:
管理容器的生命周期(从创建容器到销毁容器)
拉取/推送容器镜像
存储管理(管理镜像及容器数据的存储)
调用 runc 运行容器(与 runc 等容器运行时交互)
管理容器网络接口及网络
containerd架构图如下:
Containerd的发展史
Docker
说到Containerd,就必然绕不开Docker。Docker作为一个完整的容器引擎,其包含三个部分: 计算、存储、网络。在早期的时候,这些功能统一由docker daemon进程提供;但从docker 1.11版本开始,这些功功能开始做拆分:
计算:由containerd提供
存储:由docker-volume提供
网络:由docker-network提供
其中计算部分的架构如下:
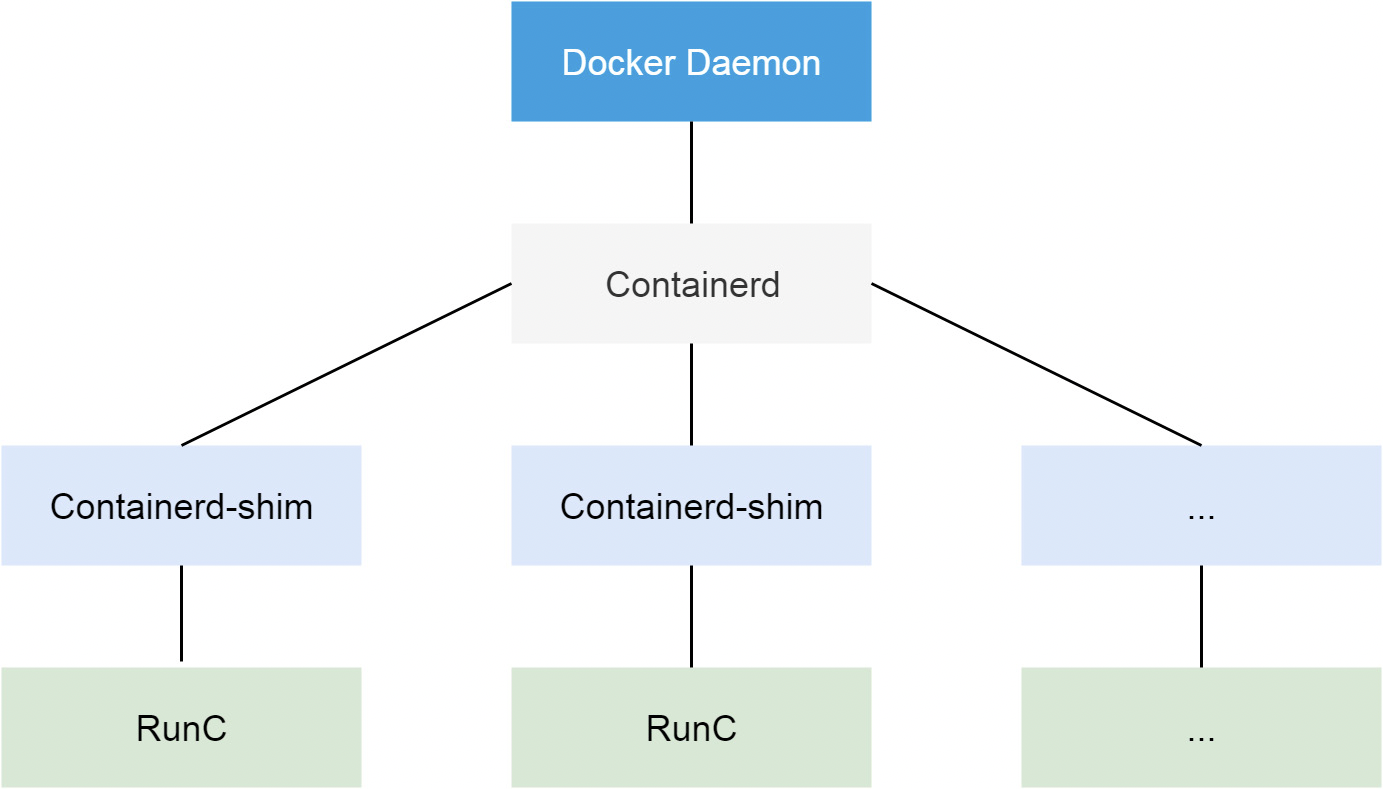
当创建容器的请求到达docker api,docker-api会调用containerd执行创建操作,此时containerd会启动一个containerd-shim进程,containerd-shim调用runc执行容器的创建操作。当容器创建完成之后, runc退出,containerd-shim作为容器的父进程收集容器的运行状态,将其上报给containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程。

runc是OCI的一个具体实现。 OCI(open container initivtive)全称为开放容器标准,其主要用于规范容器镜像的结构以及容器需要接收的操作指令,如create、start、stop、delete等命令。除了runc之外,Kata、gVisor也符合OCI规范
为什么containerd不直接调用runc,而要启动一个containerd-shim调用runc?因为容器进程是需要一个父进程来做状态收集、维持 stdin 等 fd 打开等工作的,假如这个父进程就是 containerd,那如果 containerd 挂掉的话,整个宿主机上所有的容器都会退出。引入containerd-shim则可解决这个问题
所以事实上在早期containerd一直只是作为docker创建容器的子组件而存在。
CRI
在kubernetes早期的时候,由于没法跟docker正面刚,只得通过硬编码的方式在kubelet当中直接调用Docker API创建容器。
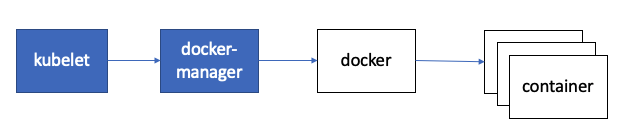
随着容器生态的逐渐发展,市面上出现了更多的容器运行时。 此时kubernetes为了支持更多的容器运行时,Google就和红帽主导了CRI标准,用于将kubernetes平台和特定的容器运行时解耦。
CRI(Container Runtime Interface 容器运行时接口)本质上就是 Kubernetes 定义的一组与容器运行时进行交互的接口,所以只要实现了这套接口的容器运行时都可以对接Kubernetes 。不过 Kubernetes 推出 CRI 这套标准的时候还没有现在的统治地位,所以有一些容器运行时自身没有实现 CRI 接口,于是就有了 shim(垫片)一个 shim 的职责就是作为适配器将各种容器运行时本身的接口适配到 Kubernetes 的 CRI 接口上,其中 dockershim就是 Kubernetes 对接 Docker 到 CRI 接口上的一个垫片实现。
Kubelet 通过 gRPC 框架与容器运行时或 shim 进行通信,其中 kubelet 作为客户端,CRI shim(也可能是容器运行时本身)作为服务器。
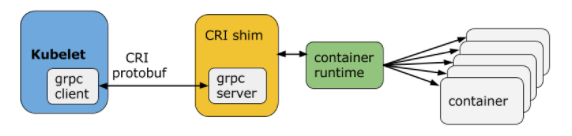
由于当时的Docker仍然处于容器生态的统治地位。kubernetes不得不在kubelet当中内置了dockershim:
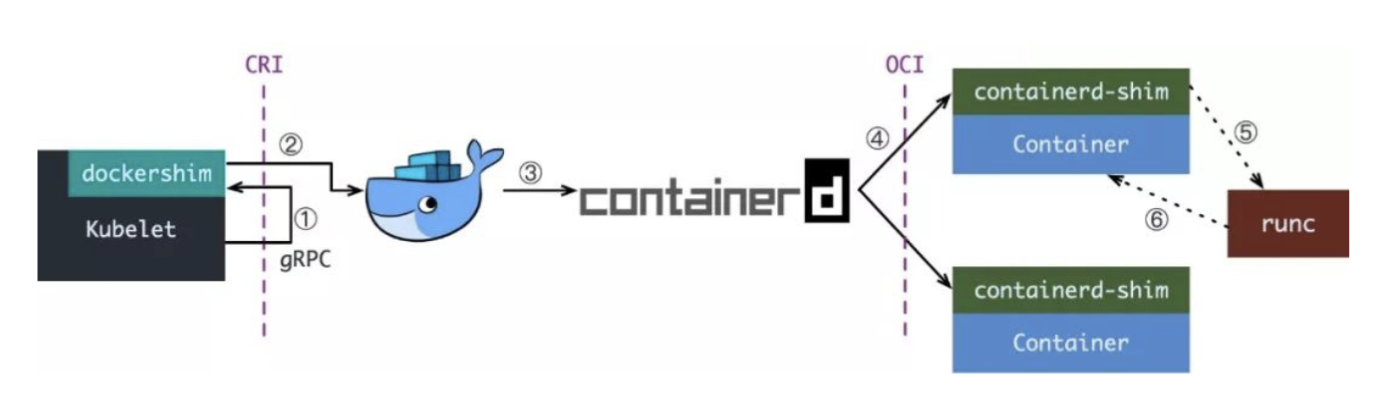
再后来,Docker在容器生态大战中败北。在2017年的时候,Docker公司将其容器运行时Containerd捐献给了CNCF。为了将containerd接入到CRI标准中,k8s又搞出了cri-containerd项目,cri-containerd是一个守护进程用来实现kubelet和containerd之间的交互,此时k8s节点上kubelet启动容器就变成了下面这个样子:

再往后,在Containerd 1.1时,将cri-containerd改成了Containerd的CRI插件,CRI插件位于containerd内部,这让k8s启动Pod时的通信更加高效:

与此同时 Kubernetes 社区也做了一个专门用于 Kubernetes 的 CRI 运行时 CRI-O,直接兼容 CRI 和 OCI 规范:
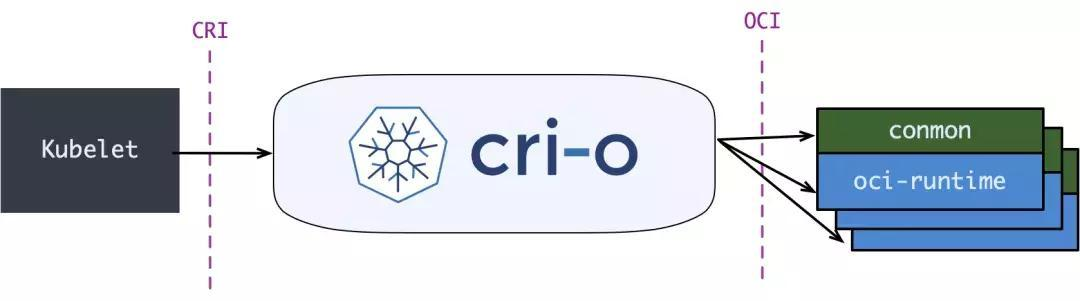
无论是CRI-O还是containerd接入kubernetes的方式都比docker使用dockershim的方式接入kubernetes要来的简单。
在2020年12月份,kubernetes宣布将在1.22版本当中正式从kubelet当中移除docker-shim代码。也就是说,如果docker仍然不支持CRI,则kubernetes将会放弃对docker的支持。而在2021年8月,kubernetes正式发布了1.22版本。
在可预见的未来,Docker最终将走下历史的舞台。而取而代之的,恰是docker自己开发的containerd。
背景
2013 年,作为小型 PaaS 公司的 dotCloud 在与老牌 PaaS 厂商的商业搏杀中被逼到了绝境。眼看就要被如火如荼的 PaaS 风潮抛弃,dotCloud 公司却做出了这样一个决定:开源自己的容器项目 Docker。
Docker 本身并没有什么新技术(其核心 namespace 和 cgroup 所提供的隔离技术在社区中一直被广泛使用),但其基于 Dockerfile 和 Docker Registry 提供的镜像打包和分发能力却完成了对传统 PaaS 诸如 Cloud Foundry、OpenShift 等的降维打击,让其还未成为对手,就被淘汰出局。
DotCloud 公司虽然通过 Docker 一举吸引了整个社区的目光,但其实其自身也面临一个很尴尬的境地:Docker 本身虽然强大,但是如果要使其真正的带来商业价值,还是需要更上层的 PaaS 平台,单靠一个 Docker 是远远不够的。于是在 2014 年,Docker 推出了自己的平台级服务 Docker Swarm,随后收购了容器编排系统 Fig,之后改名为 Docker Compose,然后又开了一个 Docker machine 永远批量管理 Docker 服务,而这三大服务也被并称为 Docker 的三架马车。这也是 Docker 的巅峰时刻。
2014 年 6 月,google 开源其容器编排系统 kubernetes,但此时 Google、RedHat 以及 CoreOS 公司仍在寻求与 Docker 公司的合作,并由 Docker 公司牵头,将其容器运行时库 LibContainer 捐献给一个完全中立的基金会,并改名为 runc。按照基金会方式运营,大家共同制定一套容器和镜像的标准和规范,这套标准和规范,就是 OCI(Open Container Initiative)。OCI 的提出,意在将容器运行时和镜像的实现从 Docker 项目中完全剥离出来。这样做,一方面可以改善 Docker 公司在容器技术上一家独大的现状,另一方面也为其他玩家不依赖于 Docker 项目构建各自的平台能力提供了可能。
但遗憾的是 OCI 并没能改变 Docker 的一家独大的现状。于是 Google、RedHat 等公司再次发起了一个名为 CNCF(Cloud Native Computing Foundation)的基金会,希望以 Kubernetes 项目为基础,建立一个由开源基础设施领域厂商主导的、按照独立基金会方式运营的容器商业生态。
随着这些顶级厂商的推动以及 kubernetes 自身的强大,越来越多的公司参与进来,最终 Docker 失败已经注定。
2017 年,Docker 公司将其容器运行时 Containerd 捐献给了 CNCF,Docker 公司宣布将在自己的主打产品 Docker 企业版中内置 Kubernetes 项目,这标志着持续了近两年之久的 “编排之争” 至此落下帷幕。
2020 年底,Kubernetes 官方宣布将会在其 1.22 版本当中正式放弃对 Docker 的支持。因为 Docker 一直不支持 kubernetes 的官方的 CRI,Kubernetes 为了兼容 Docker,在其 kubelet 组件中开放了一个被称之为 docker-shim 的一个插件用以提供对 Docker 接口的兼容。事实上,所谓放弃对 Docker 的支持,就是将这段代码从 kubelet 当中清理掉。
三、Containerd快速入门指南
Containerd官方网站: containerd – An industry-standard container runtime with an emphasis on simplicity, robustness and portability
Containerd代码托管地址: containerd/containerd: An open and reliable container runtime (github.com)
containerd
安装containerd:
# step 1: 安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3
sudo sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
yum install -y containerd
systemctl enable containerd --now
systemctl status containerd修改containerd配置文件:
可以使用如下方式生成containerd的默认配置文件:
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml修改配置文件示例如下:
......
[plugins]
......
[plugins."io.containerd.grpc.v1.cri"]
...
#sandbox_image = "k8s.gcr.io/pause:3.2"
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.5"
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# 该不存在,要添加
SystemdCgroup = true #对于使用 systemd 作为 init system 的 Linux 的发行版,使用 systemd 作为容器的 cgroup driver 可以确保节点在资源紧张的情况更加稳定
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://pqbap4ya.mirror.aliyuncs.com"]
......重启containerd:
systemctl restart containerdnerdctl
部署nerdctl:
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/softwares/linux/kubernetes/nerdctl-full-0.14.0-linux-amd64.tar.gz
tar xf nerdctl-full-0.14.0-linux-amd64.tar.gz -C /usr/ buildkit
buildkit代码托管地址: https://github.com/moby/buildkit
简介
使用nerdctl无法直接通过containerd构建镜像,需要与buildkit组全使用以实现镜像构建。
buildkit项目是Docker公司开源出来的一个构建工具包,支持OCI标准的镜像构建。它主要包含以下部分:
服务端buildkitd,当前支持runc和containerd作为worker,默认是runc
客户端buildctl,负责解析Dockerfile,并向服务端buildkitd发出构建请求
buildkit是典型的C/S架构,client和server可以不在一台服务器上。而nerdctl在构建镜像方面也可以作为buildkitd的客户端。
安装
获取buildkit安装包并解压至/usr/local/目录:
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/softwares/linux/kubernetes/buildkit-v0.9.0.linux-amd64.tar.gz
tar xf buildkit-v0.9.0.linux-amd64.tar.gz -C /usr/local/配置buildkit的启动文件,可以从这里下载: https://github.com/moby/buildkit/tree/master/examples/systemd
# vim /etc/systemd/system/buildkit.socket
[Unit]
Description=BuildKit
Documentation=https://github.com/moby/buildkit
[Socket]
ListenStream=%t/buildkit/buildkitd.sock
SocketMode=0660
[Install]
WantedBy=sockets.target
# vim /etc/systemd/system/buildkit.service
[Unit]
Description=BuildKit
Requires=buildkit.socket
After=buildkit.socket
Documentation=https://github.com/moby/buildkit
[Service]
# Replace runc builds with containerd builds
ExecStart=/usr/local/bin/buildkitd --addr fd://
[Install]
WantedBy=multi-user.target启动buildkit:
systemctl daemon-reload
systemctl enable buildkit --now附录-异常处理
xfs文件系统导致containerd异常
如果安装containerd的节点使用的根分区为xfs文件系统,这时可通过xfs_info /检查xfs文件系统属性: `
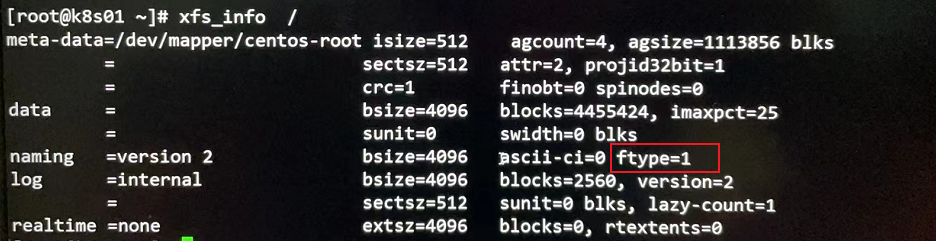
如果发现ftype=0时,则containerd无法正常工作,在拉取镜像时会抛如下异常:
failed to pull image "registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.0": output: time="2022-03-17T17:22:20+08:00" level=fatal msg="pulling image: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.ImageService"
, error: exit status 1可以通过如下方式配置xfs文件系统:
mkfs.xfs -n ftype=1 /dev/sda1容器使用overlay文件系统,而在xfs当中,只有当 d_type=true 时,overlay 和 overlay2 才被 xfs 文件系统支持。d_type 从 Linux 2.6 内核开始就已经支持了,只不过 Linux 内核虽然支持,但有些文件系统实现了 d_type,而有些没有实现,有些是选择性的实现,也就是需要用户自己用额外的参数来决定是否开启d_type的支持。在xfs中,ftype用来决定是否支持d_type,1表示支持,0表示不支持。
参考: Docker的OverlayFS存储驱动 - 知乎 (zhihu.com)
四、Containerd的部署与配置
containerd部署
安装containerd有两种方式,一种是直接下载二进制包解压即可,另一种是通过配置yum源安装。
二进制部署
在containerd的下载页面,有两种类型的包:
一种是以containerd开头的包,此包只包含containerd本身,要想真正运行起来,还需要依赖runc以及cni
一种是以cri-containerd-cni开头的包,此包除了包含containerd本身,还包含了containerd运行所依赖的相关组件,包括runc,cni以及ctr和crictl管理工具
这里使用cri-containerd-cni开头的包:
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/softwares/linux/kubernetes/cri-containerd-cni-1.5.8-linux-amd64.tar.gz
tar xf cri-containerd-cni-1.5.8-linux-amd64.tar.gz -C /
# 启动
systemctl daemon-reload
systemctl enable containerd --now需要说明的是,实际测试cri-containerd-cni-1.5.8-linux-amd64.tar.gz这个包中 所带的runc无法正常使用:
# runc --version
containerd/usr/local/sbin/runc: symbol lookup error: containerd/usr/local/sbin/runc: undefined symbol: seccomp_api_get可以从runc官方下载runc的二进制包替换即可。
runc的官方代码托管地址: https://github.com/opencontainers/runc
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/softwares/linux/kubernetes/runc-1.0.2
mv runc-1.0.2 /usr/local/sbin/runc
chmod +x /usr/local/sbin/runc
# 验证
# runc --version
runc version 1.0.2
commit: v1.0.2-0-g52b36a2dd837
spec: 1.0.2-dev
go: go1.16.7
libseccomp: 2.5.1
yum源部署
# step 1: 安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3
sudo sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
yum install -y containerd
systemctl enable containerd --now
systemctl status containerd修改containerd配置文件:
可以使用如下方式生成containerd的默认配置文件:
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml修改配置文件示例如下:
......
[plugins]
......
[plugins."io.containerd.grpc.v1.cri"]
...
#sandbox_image = "k8s.gcr.io/pause:3.2"
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.5"
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
#对于使用 systemd 作为 init system 的 Linux 的发行版,使用 systemd 作为容器的 cgroup driver 可以确保节点在资源紧张的情况更加稳定
SystemdCgroup = true
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://pqbap4ya.mirror.aliyuncs.com"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"]
endpoint = ["https://registry.aliyuncs.com/k8sxio"]
......最新的镜像仓库配置示例: containerd Registry Configuration | Gardener
修改内核参数:
# vim /etc/sysctl.conf
fs.may_detach_mounts = 1
sysctl -p 重启containerd:
systemctl restart containerd客户端工具nerdctl
nerdctl 是由containerd官方开发的一个docker兼容的命令行管理工具。
nerdctl的代码托管地址: https://github.com/containerd/nerdctl
nerdctl有两个包:
nerdctl:只包含了nerdctl客户端
nerdctl-full:除了nerdctl客户端,还有containerd的相关工具runc以及cni插件
如果使用cri-containerd-cni-1.5.8-linux-amd64.tar.gz这个包通过二进制方式安装的containerd,则客户端只需要安装nerdctl;如果使用的是yum安装的containerd,则客户端需要安装nerdctl-full
下面是安装nerdctl-full包的示例:
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/softwares/linux/kubernetes/nerdctl-full-0.14.0-linux-amd64.tar.gz
tar xf nerdctl-full-0.14.0-linux-amd64.tar.gz -C /usr/常用配置说明
1. 配置镜像加速器
找到[plugins.cri.registry]配置项,并修改内容如下:
[plugins.cri.registry]
[plugins.cri.registry.mirrors]
[plugins.cri.registry.mirrors."docker.io"]
#endpoint = ["https://registry-1.docker.io"]
endpoint = ["https://o0o4czij.mirror.aliyuncs.com"]2.配置非安全的私有仓库
[plugins.cri.registry.mirrors."192.168.0.1:5000"]
endpoint = ["http://192.168.0.1:5000"]3.配置带认证的非安全的私有仓库
[plugins.cri.registry.mirrors."192.168.0.1:5000"]
endpoint = ["http://192.168.0.1:5000"]
[plugins.cri.registry.configs."192.168.0.1:5000".auth]
username = "admin"
password = "Harbor12345"4.配置使用自签名的ssl证书的私有仓库
plugins.cri.registry.mirrors."hub.example.com"]
endpoint = ["https://hub.example.com"]
[plugins.cri.registry.configs."hub.example.com".auth]
username = "admin"
password = "Harbor12345"
[plugins.cri.registry.configs."hub.example.com".tls]
ca_file = "/opt/certs/ca.crt"5.containerd配置示例
version = 2
root = "/var/lib/containerd"
state = "/run/containerd"
[grpc]
address = "/run/containerd/containerd.sock"
uid = 0
gid = 0
max_recv_message_size = 16777216
max_send_message_size = 16777216
[ttrpc]
address = ""
uid = 0
gid = 0
[debug]
address = ""
uid = 0
gid = 0
level = ""
[metrics]
address = ""
grpc_histogram = false
[cgroup]
path = ""
[timeouts]
"io.containerd.timeout.shim.cleanup" = "5s"
"io.containerd.timeout.shim.load" = "5s"
"io.containerd.timeout.shim.shutdown" = "3s"
"io.containerd.timeout.task.state" = "2s"
[plugins]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.cn-beijing.aliyuncs.com/kubesphereio/pause:3.9"
[plugins."io.containerd.grpc.v1.cri".cni]
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"
max_conf_num = 1
conf_template = ""
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://registry-1.docker.io"]附录-异常处理
xfs文件系统导致containerd异常
如果安装containerd的节点使用的根分区为xfs文件系统,这时可通过xfs_info /检查xfs文件系统属性: `
如果发现ftype=0时,则containerd无法正常工作,在拉取镜像时会抛如下异常:
failed to pull image "registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.0": output: time="2022-03-17T17:22:20+08:00" level=fatal msg="pulling image: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.ImageService"
, error: exit status 1可以通过如下方式配置xfs文件系统:
mkfs.xfs -n ftype=1 /dev/sda1容器使用overlay文件系统,而在xfs当中,只有当 d_type=true 时,overlay 和 overlay2 才被 xfs 文件系统支持。d_type 从 Linux 2.6 内核开始就已经支持了,只不过 Linux 内核虽然支持,但有些文件系统实现了 d_type,而有些没有实现,有些是选择性的实现,也就是需要用户自己用额外的参数来决定是否开启d_type的支持。在xfs中,ftype用来决定是否支持d_type,1表示支持,0表示不支持。
参考:Docker的OverlayFS存储驱动 - 知乎 (zhihu.com)
五、Containerd容器管理
容器管理
运行容器
1.运行一个容器示例:
# 启动一个httpd容器,使其在后台运行并将其80端口映射到宿主机80端口
nerdctl run -d -p 80:80 httpd2.将容器在前台运行:
# 启动一个ubuntu 16.04的容器,打印完"hello world"即退出
nerdctl run ubuntu:16.04 /bin/echo " hello world "
# 在前台运行容器并进入容器与容器交互
nerdctl run ubuntu:16.04 /bin/bash需要说明的是,容器是为任务而生的。一个容器建议只运行一个进程,而且这个进程需要在容器的前台运行,不能通过daemon的方式运行。如果进程退出,容器也会随之停止
3.容器的启动过程说明:
检查本地是否存在指定的镜像,如果没有就从指定的仓库下载
利用镜像启动一个容器
分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
从宿主机配置的网桥接口中桥接一个虚拟接口到容器中去
从地址池配置一个IP给容器
执行用户指定的程序
执行完毕后停止容器
4.将容器放入后台运行:
nerdctl run -d ubuntu:16.04 /bin/bash -c "while true; do echo hello world; sleep 1;done"5.docker run常用选项说明
-t:配置一个伪终端并绑定到容器的标准输入上
-i:让容器的标准输入保持打开
-d:将容器放入后台运行
-p: 为容器配置端口映射
--dns: 为容器指定dns地址
--name: 为容器指定名称
-e:在容器启动时为其传递环境变量
-workdir: 指定工作目录
--restart:指定容器退出时是否重启
--rm: 在容器退出时,自动删除
-v:挂载数据卷
6.查看当前节点上的容器状态
nerdctl ps #查看当前正在运行的容器
选项:
-a:查看所有容器,包括停止的
-q:只显示容器ID7.进入容器
nerdctl exec -it <容器id/容器name> /bin/bash8.运行容器的最佳实践
容器按用途大致可分为两类:
服务类容器,如webserver、database等
工具类容器,如curl容器、redis-cli容器等
通常而言,服务类容器需要长期运行,所以使用daemon的方式运行;而工作类环境通常是给我们提供一个临时的工作环境,所以一般以run –ti的方式在前台运行
容器的启停操作
# 容器的启动:
nerdctl start <容器id>
# 容器的停止:
nerdctl stop <容器id>
nerdctl kill <容器id>
# 容器的重启:
nerdctl restart <容器id>
# 容器的删除:
nerdctl rm <容器id>
选项:
-f:强行终止并删除一个运行中的容器
-v:删除容器挂载的数据卷
# 暂停容器:
nerdctl pause <容器id>
# 从暂停中恢复:
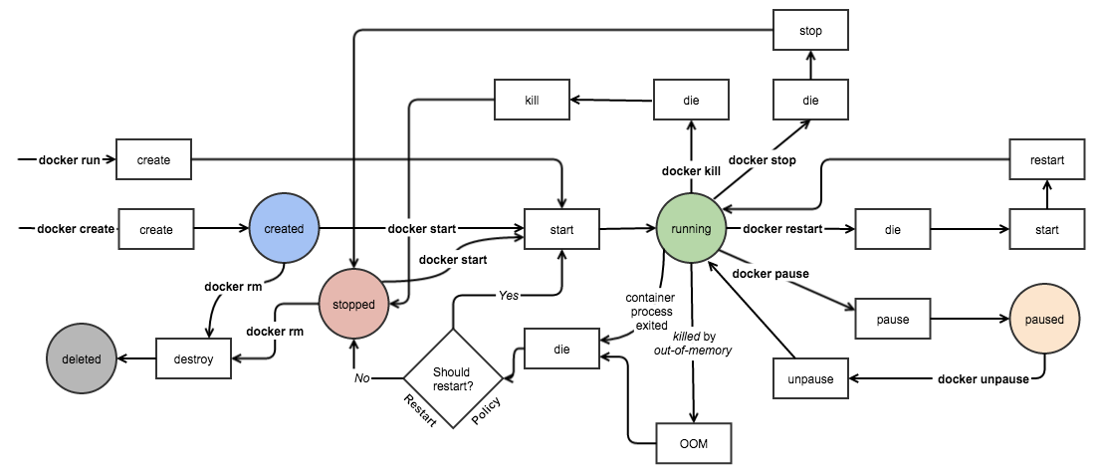
nerdctl unpause <容器id>容器生命周期管理
容器资源限制
一个宿主机上会运行若干容器,每个容器都需要CPU、内存和 IO 资源。对于 KVM,VMware等虚拟化技术,用户可以控制分配多少 CPU、内存资源给每个虚拟机。对于容器,Contianerd也提供了类似的机制避免某个容器因占用太多资源而影响其他容器乃至整个 host 的性能。
内存限制
启动一个ubuntu容器,限制内存为200M, 内存与swap的总和为300M:
nerdctl run -it -m 200M --memory-swap 300M ubuntu:16.04选项说明:
-m:允许分配的内存大小下面是一个压测示例:
nerdctl run -it -m 200M progrium/stress --vm 1 --vm-bytes 180M
选项:
--vm:设置内存工作线程数
--vm-byptes:设置单个内存工作线程使用的内存大小上面的示例中,--vm-bytes为180M,容器工作正常;如果将其修改为230M,则容器OOM退出
关于内存资源的更多限制可以参考这里:https://blog.opskumu.com/docker-memory-limit.html
CPU限制
默认情况下,所有容器可以平等的使用宿主机cpu资源且没有限制。nerdctl可以通过--cpu-shares设置容器使用的cpu的权重,默认为1024。与内存限额不同,通过 --cpu-shares设置的 cpu share 并不是 CPU 资源的绝对数量,而是一个相对的权重值。某个容器最终能分配到的 CPU 资源取决于它的 cpu share 占所有容器 cpu share 总和的比例。
换句话说:通过cpu share可以设置容器使用CPU的优先级。
例如,在host中启动了两个容器:
nerdctl run --name container_A --cpu-shares 1024 ubuntu:16.04
nerdctl run --name container_B --cpu-shares 512 ubuntu:16.04container_A的cpu share 1024,是 container_B 的两倍。当两个容器都需要 CPU 资源时,container_A可以得到的 CPU 是container_B的两倍。
需要特别注意的是,这种按权重分配CPU只会发生在CPU 资源紧张的情况下。如果
container_A处于空闲状态,这时,为了充分利用CPU资源,container_B也可以分配到全部可用的 CPU。
下面是一个压测示例:
# --cpu用于设置cpu工作线程的数量,有几个核就设置为几
nerdctl run --name "container_A" --cpu-shares 1024 progrium/stress --cpu 1
nerdctl run --name "container_B" --cpu-shares 512 progrium/stress --cpu 1两个容器运行起来之后,可以通过在宿主机上使用top查看cpu的资源消耗可以看到两个容器的cpu消耗。
除了使用--cpu-shares设置cpu权重,也可以通过--cpus设置cpu的核心数。还可以通过设置--cpuset-cpus参数设置将当前容器的进程数绑定在指定cpu上运行。
关于cpu资源的更多限制可以参考这里:https://blog.opskumu.com/docker-cpu-limit.html
镜像管理
镜像命名规范
无论我们对镜像做何种操作,首先它得有个名字。我们在前面使用docker run来运行容器的时候,就需要传递一个镜像名称,容器基于该镜像来运行。
一个完整的镜像名称由两部分组成:
<imageName> = <repository>:[tag]其中repository包含如下内容:
[Registry/][Namespace/]<Name>所以一个完整的镜像命名如下:
[Registry/][Namespace/]<Name>:[tag]示例:
hub.breezey.top/op-base/openresty:1.13
hub.breezey.top/op-base/php:7.0.31-fpm-centos7
mysql:5.6
ubuntu当没指明镜像tag时,默认为latest,但latest没有任何特殊含义,在docker hub上很多repository将latest作为最新稳定版本的别名,但这只是一种约定,不是强制规定,一个repository可以有多个tag,而多个tag也可能对应同一个镜像
镜像基本操作
1.获取镜像
nerdctl pull centos:7 #直接从docker hub获取镜像
nerdct lpull registry.cn-zhangjiakou.aliyuncs.com/breezey/mysql:5.7 #从dockerpool获取镜像2.查看镜像信息
nerdctl image ls
nerdctl inspect centos:7 #获取镜像的详细信息3.为镜像创建tag
nerd tag centos:7 registry.cn-zhangjiakou.aliyuncs.com/breezey/centos:74.删除镜像(注:如果镜像有容器生成,需要先删除容器)
#如果一个镜像有多个tag,只会删除指定的tag,镜像本身不会删除,如果docker rmi后指定镜像ID,则所有tag都会被删除
nerdctl rmi centos:75.通过docker commit提交一个新镜像
nerdctl commit -m "Add a new file" -a "Breeze" a925cb40b3f0 test #使用a925cb40b3f0容器生成一个名为test的镜像
-a:指定作者
-m:相关说明信息
-p:提交时暂停容器运行附录-异常处理
1.runc命令运行异常
如果在使用nerdctl运行容器时出现如下错误:

需要更新下libseccomp包:
yum install -y libseccomp-devel当使用cri-containerd-cni 1.5.8版本时,runc报错通过安装libseccomp-devel无法修复,此时可使用nerdctl-full包中的runc替换cri-containerd-cni包中的runc即可。
六、Containerd网络管理
containerd自身并不具备为容器提供网络的能力。需要结合CNI为容器配置网络。
CNI简介
CNI (Container Network Interface)是CNCF的一个开源项目,其包含一些用于配置linux容器网络接口的规范、库,以及一些支持插件。CNI只关心容器创建时的网络分配,以及当容器被删除时已经分配网络资源的释放。 CNI作为容器网络的标准,使得各个容器管理平台可以通过相同的接口调用各种各样的网络插件来为容器配置网络。
我们在安装cri-containerd-cni的时候,已经安装好了cni插件以及相关工具,可以在/opt/cni/bin目录下查看相关可执行文件。这些执行文件从功能角度可以分为如下三类:
主插件: 用于创建网络设备
bridge: 创建一个网桥设备,并添加宿主机和容器到该网桥
ipvlan: 为容器添加ipvlan网络接口
loopback: 设置lo网络接口的状态为up
macvlan: 创建一个新的MAC地址,并将所有流量转发到容器
ptp: 创建Veth对
vlan: 分配一个vlan设备
host-device: 将已存在的设备移入容器内
IPAM插件: 用于IP地址的分配
dhcp: 在宿主机上运行dhcp守护程序,代表容器发出dhcp请求
host-local: 维护一个分配ip的本地数据库
static: 为容器分配一个静态IPv4/IPv6地址,主要用于调试
Meta插件: 其他插件,非单独使用插件
flannel: flannel网络方案的CNI插件,根据flannel的配置文件创建网络接口
tuning: 调整现有网络接口的sysctl参数
portmap: 一个基于iptables的portmapping插件。将端口从主机的地址空间映射到容器
bandwidth: 允许使用TBF进行限流的插件
sbr: 一个为网络接口配置基于源路由的插件
firewall: 过iptables给容器网络的进出流量进行一系列限制的插件
containerd网络配置
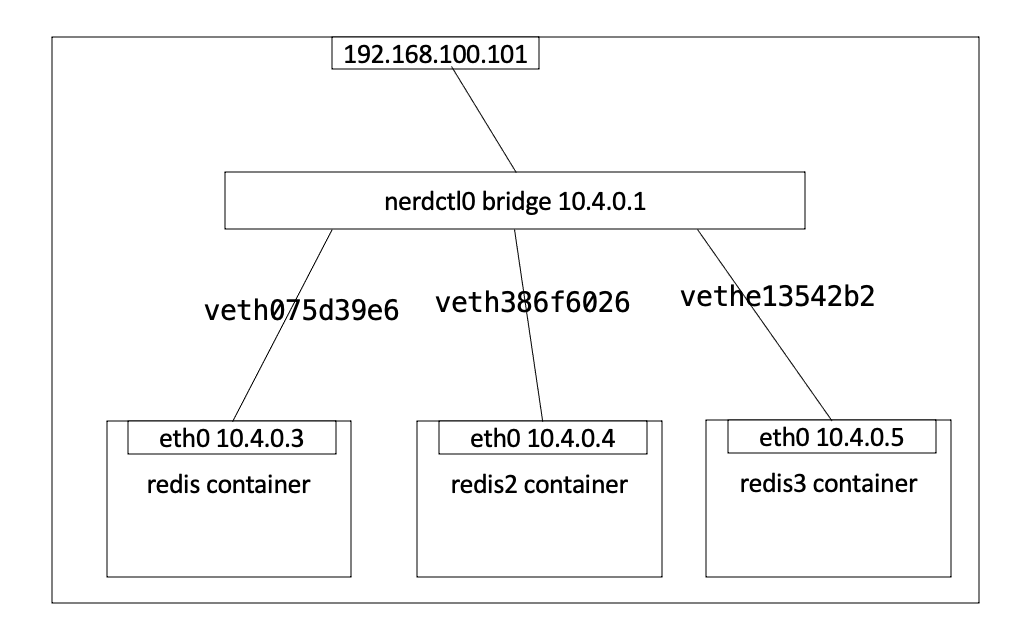
默认情况下,当安装好cni插件和工具后,使用nerdctl启动了一个容器之后,宿主机上会出现一个nerdctl0网桥:
[root@ecs-350c-0001 ~]# ip addr show nerdctl0
3: nerdctl0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 96:97:3c:08:11:cf brd ff:ff:ff:ff:ff:ff
inet 10.4.0.1/24 brd 10.4.0.255 scope global nerdctl0
valid_lft forever preferred_lft forever
inet6 fe80::9497:3cff:fe08:11cf/64 scope link
valid_lft forever preferred_lft forever此时创建出来的容器将获得与网桥同网段的ip,并将网关指向网桥,连接示意图如下:
除了默认的bridge网桥模式,containerd还支持host、none以及自定义网络,可以通过如下方式查看containerd支持的容器网络:
[root@ecs-350c-0001 ~]# nerdctl network ls
NETWORK ID NAME FILE
0 bridge
containerd-net /etc/cni/net.d/10-containerd-net.conflist
host
none bridge网络
bridge是containerd的默认网络模式,可以通过如下指令查看bridge的详细配置信息:
[root@ecs-350c-0001 ~]# nerdctl network inspect bridge
[
{
"Name": "bridge",
"Id": "0",
"IPAM": {
"Config": [
{
"Subnet": "10.4.0.0/24",
"Gateway": "10.4.0.1"
}
]
},
"Labels": {}
}
]创建使用bridge网络容器的示例:
nerdctl run -d --name web1 --net bridge nginx基于bridge网络的容器访问外部网络
默认情况下,基于bridge网络容器即可访问外部网络,这是因为默认情况下,bridge使用了iptables的snat转发来实现容器对外部的访问。
外部网络访问基于bridge网络的容器
如果想让外界可以访问到基于bridge网络创建的容器提供的服务,需要为容器配置端口映射:
nerdctl run -d -p 80:80 --name web nginx:1.21这种端口映射基于iptables的dnat实现
查看容器的端口情况:
nerdctl port webnone网络
故名思议,none网络就是什么都没有的网络。使用none网络的容器除了lo,没有其他任何网卡,完全隔离。用于既不需要访问外部服务,也不允许外部服务访问自己的应用场景。
查看none网络信息:
nerdctl network inspect none创建使用none网络容器的示例:
nerdctl run -d --name web_none --net none nginxhost网络
使用host网络的主机,与宿主机共享网络地址,可以获得最好的数据转发性能。缺点是,同一个宿主机上的多个容器共享同一个ip地址,如果多容器使用相同的端口,需要自行解决端口冲突问题。
同样的,可以通过如下方式查看host网络信息:
nerdctl network inspect host创建一个使用host网络容器的示例:
# 可以看到该容器没有自己的IP地址,因为它直接使用宿主机IP地址
nerdctl run -d --name web_host -net host nginx自定义网络
我们可以通过cni的插件和工具轻松的为containerd自定义网络。
自定义bridge网络
我们在执行nerdctl network ls时,可以看到有一个自定义的网络名为containerd-net,其配置文件路径为/etc/cni/net.d/10-containerd-mynet.conflist内容如下:
{
"cniVersion": "0.4.0",
"name": "containerd-net",
"plugins": [
{
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"promiscMode": true,
"ipam": {
"type": "host-local",
"ranges": [
[{
"subnet": "10.88.0.0/16"
}],
[{
"subnet": "2001:4860:4860::/64"
}]
],
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "::/0" }
]
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true}
}
]
}这是一个自定义的bridge网络, 我们可以通过如下指令创建一个容器使用该网络:
nerdctl run -d --name web2 --net containerd-net nginx自定义flannel网络
从上面的例子中,我们知道,对于containerd的自定义网络。只要安装对应的网络插件,然后定义cni配置文件即可。而对于像flannel这种可以配置跨主机网络互联的网络插件,cni只为我们提供了配置网络的工具,而并没有安装flannel,需要我们自行安装。
flannel代码托管地址: flannel-io/flannel: flannel is a network fabric for containers, designed for Kubernetes (github.com)
flannel cni网络配置工具代码托管地址: coreos/flannel-cni: Image for sidecar container that installs cni related assets for flannel (github.com)
部署etcd
flannel网络依赖etcd, 所以需要先安装etcd:
nerdctl run -d --net host --name etcd -v /var/lib/etcd:/var/lib/etcd registry.cn-zhangjiakou.aliyuncs.com/breezey/etcd:v3.5.0 \
etcd --name etcd \
--data-dir /var/lib/etcd \
--listen-client-urls http://192.168.0.180:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://192.168.0.180:2379,http://127.0.0.1:2379 \
--listen-peer-urls http://localhost:2380,http://192.168.0.180:2380 \
--enable-v2 # flannel目前仍然只支持etcd v2,所以需要将v2 api开启安装flannel
往etcd当中写入flannel的网段:
# 安装etcd客户端
yum install -y etcd
# 使用etcd v2 api向etcd中添加flannel的网段
export ETCDCTL_API=2;etcdctl --endpoints http://127.0.0.1:2379 set /coreos.com/network/config \
'{"Network": "10.0.0.0/16", "SubnetLen": 24, "SubnetMin": "10.0.1.0","SubnetMax": "10.0.20.0", "Backend": {"Type": "vxlan"}}'安装flannel:
nerdctl run -d --privileged -v /run/flannel:/run/flannel --net host --name flannel registry.cn-zhangjiakou.aliyuncs.com/breezey/flannel:v0.14.0 \
-etcd-prefix /coreos.com/network -iface eth0 -etcd-endpoints http://192.168.0.180:2379 -ip-masq 为flannel配置cni:
# vim /etc/cni/net.d/10-flannel.conflist
{
"name": "flannel",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}关于flannel的cni配置,可参考: flannel-cni/flannel.conflist.default at master · coreos/flannel-cni (github.com)
此时查看containerd网络:
[root@ecs-350c-0001 net.d]# nerdctl network ls
NETWORK ID NAME FILE
0 bridge
containerd-net /etc/cni/net.d/10-containerd-net.conflist
flannel /etc/cni/net.d/10-flannel.conflist
host
none 由于containerd-net网络在创建时会使用cni0,而flannel网络在创建时也会使用cni0,会出现冲突,所以这里先把containerd-net网络干掉:
# 清掉所有容器
nerdctl ps -aq |xargs nerdctl rm
# 停掉cni0接口
ifconfig cni0 down
# 删除cni0接口
yum install -y bridge-utils
brctl delbr cni0
# 移除containerd-net配置文件
mv /etc/cni/net.d/10-containerd-net.conflist /tmp/此时创建一个使用flannel网络的容器即可:
[root@ecs-350c-0001 net.d]# nerdctl run -d --net flannel --name flannel busybox:1.28 sleep 3600
07a5035f7836b5331c849912df71861fd22ad8c3bf257be81a8c9f36132d5034再次查看cni0的宿主机网络:
# ip a
...
39: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 76:16:d1:84:98:60 brd ff:ff:ff:ff:ff:ff
inet 10.0.7.0/32 brd 10.0.7.0 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::7416:d1ff:fe84:9860/64 scope link
valid_lft forever preferred_lft forever
43: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether 66:d4:88:0c:eb:7d brd ff:ff:ff:ff:ff:ff
inet 10.0.7.1/24 brd 10.0.7.255 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::64d4:88ff:fe0c:eb7d/64 scope link
valid_lft forever preferred_lft forever
...查看busybox的网络:
[root@ecs-350c-0001 net.d]# nerdctl exec -it busybox ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: eth0@if44: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether ea:2e:f7:96:b8:19 brd ff:ff:ff:ff:ff:ff
inet 10.0.7.3/24 brd 10.0.7.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::e82e:f7ff:fe96:b819/64 scope link
valid_lft forever preferred_lft forever至此,flannel网络配置完成。将其他宿主机的网络也接入该flannel网络,则可实现跨宿主机的容器网络互联。
七、Containerd镜像构建
buildkit
buildkit代码托管地址: https://github.com/moby/buildkit
简介
使用nerdctl无法直接通过containerd构建镜像,需要与buildkit组全使用以实现镜像构建。
buildkit项目是Docker公司开源出来的一个构建工具包,支持OCI标准的镜像构建。它主要包含以下部分:
服务端buildkitd,当前支持runc和containerd作为worker,默认是runc
客户端buildctl,负责解析Dockerfile,并向服务端buildkitd发出构建请求
buildkit是典型的C/S架构,client和server可以不在一台服务器上。而nerdctl在构建镜像方面也可以作为buildkitd的客户端。
安装
获取buildkit安装包并解压至/usr/local/目录:
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/softwares/linux/kubernetes/buildkit-v0.9.0.linux-amd64.tar.gz
tar xf buildkit-v0.9.0.linux-amd64.tar.gz -C /usr/local/配置buildkit的启动文件,可以从这里下载: https://github.com/moby/buildkit/tree/master/examples/systemd
# vim /etc/systemd/system/buildkit.socket
[Unit]
Description=BuildKit
Documentation=https://github.com/moby/buildkit
[Socket]
ListenStream=%t/buildkit/buildkitd.sock
SocketMode=0660
[Install]
WantedBy=sockets.target
# vim /etc/systemd/system/buildkit.service
[Unit]
Description=BuildKit
Requires=buildkit.socket
After=buildkit.socket
Documentation=https://github.com/moby/buildkit
[Service]
# Replace runc builds with containerd builds
ExecStart=/usr/local/bin/buildkitd --addr fd://
[Install]
WantedBy=multi-user.target启动buildkit:
systemctl daemon-reload
systemctl enable buildkit --now构建示例
构建一个nginx镜像
下面是一个简单的dockerfile示例:
# 添加引用的基础镜像
FROM centos:7
# 添加注解
LABEL Author natasha<natasha@example.com> \
Time 20210911 \
function nginx-demo
# 镜像构建
ADD repos.tar.gz /etc/yum.repos.d/
#COPY repos.tar.gz /etc/yum.repos.d/
#ADD CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo
#ADD epel.repo /etc/yum.repos.d/epel.repo
RUN yum install -y nginx && \
rm -rf /usr/share/nginx/html/* && \
echo "hello world" > /usr/share/nginx/html/index.html
# 容器启动时执行的操作
CMD ["nginx","-g", "daemon off;"]执行构建:
nerdctl build -t nginx:custom .多阶段构建
下面是一个简单的golang的web应用示例:
package main
import (
"io"
"log"
"net/http"
)
func main() {
handler := func(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "Hello, world!\n")
}
http.HandleFunc("/hello", handler)
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Fatal(err)
}
}多阶段构建的dockerfile示例:
FROM golang:1.16.4-alpine3.13 as builder
WORKDIR /go/src/hello
COPY main.go .
ENV GO111MODULE=off
RUN go build .
FROM hub.example.com/ops/centos:7
WORKDIR /app/
COPY --from=0 /go/src/hello/hello .
CMD ["./hello"]
EXPOSE 8080执行构建:
nerdctl build -t go-web-hello .构建中使用ARG传参
在Dockerfile里,我们可以用 ARG 指令来建立一个参数变量,我们可以在构建时通过构建指令传入这个参数变量,并且在 Dockerfile 里使用它。下面是一个简单的示例:
FROM debian:stretch-slim
## ......
# 定义两个ARG,等待构建时传入
ARG TOMCAT_MAJOR
ARG TOMCAT_VERSION
# 将其中一个ARG的值设置为环境变量
ENV TOMCAT_VERSION ${TOMCAT_VERSION}
## ......
# 使用ARG参数
RUN wget -O tomcat.tar.gz "https://www.apache.org/dyn/closer.cgi?action=download&filename=tomcat/tomcat-$TOMCAT_MAJOR/v$TOMCAT_VERSION/bin/apache-tomcat-$TOMCAT_VERSION.tar.gz"
## ......此时,在构建时可通过如下方式将参数传入:
nerdctl build --build-arg TOMCAT_MAJOR=8 --build-arg TOMCAT_VERSION=8.0.53 -t tomcat:8.0 ./tomcat八、Containerd使用相关问题
1. insecure registry
无论是docker还是containerd,默认拉取镜像的镜像仓库必须是https,而且证书还必须是受信的。如果是在自测环境使用了http或者虽然是https,但证书是自签的。这时就会出现无法从该镜像仓库拉取镜像的问题,抛出的异常如下:
FATA[0000] Get "https://hub.example.com/v2/": x509: certificate signed by unknown authority在docker里面,我们可以通过修改daemon.json,添加如下配置项解决:
{
"insecure-registries": ["https://hub.example.com"]
}在containerd中的解决方式就稍微有点儿复杂。因为containerd的命令行管理工具有如下三种:
ctr
crictl
nerdctl
针对不同的命令行工具,解决办法还不一样。
crictl
先说针对crictl的解决办法,也是在kubernetes当中的解决办法(因为crictl是kubernetes官方提供的cri管理工具)。可以通过修改/etc/containerd/config.toml配置文件来处理,需要添加如下配置项:
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
...
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."hub.example.com"]
endpoint = ["https://hub.example.com"] # 如果是http,则这里直接写http即可
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.configs."hub.example.com".tls]
insecure_skip_verify = true # 不校验证书然后重启containerd:
systemctl restart containerdctr
ctr针对http类型的镜像仓库和不受信https类型的镜像仓库的处理方式还不太一样。
针对http类型的镜像仓库,拉取镜像可使用如下指令:
ctr i pull --plain-http hub.example.com/library/centos:7.6 # 这里假设registry地址为http://hub.example.com针对不受信https类型的镜像仓库,拉取镜像可使用如下指令:
ctr i pull -k hub.example.com/library/centos:7.6 # 这里假设registry地址为https://hub.example.comnerdctl
在使用nerdctl从不受信的镜像仓库中拉取镜像时,需要使用—insecure-registry参数,示例如下:
# nerdctl --insecure-registry=true login --username admin --password Harbor12345 https://hub.example.com
WARN[0000] WARNING! Using --password via the CLI is insecure. Use --password-stdin.
WARN[0000] insecure registry https://hub.example.com should not contain 'https://' and 'https://' has been removed from the insecure registry config
Login Succeeded
# nerdctl --insecure-registry=true push hub.example.com/library/centos:7.6
INFO[0000] pushing as a single-platform image (application/vnd.docker.distribution.manifest.v2+json, sha256:9b79c0dfb92dadac79a34c185aab6ffd208905a2eead6586626b735dc8b714d4)
WARN[0000] skipping verifying HTTPS certs for "hub.example.com"
manifest-sha256:9b79c0dfb92dadac79a34c185aab6ffd208905a2eead6586626b735dc8b714d4: waiting |--------------------------------------|
layer-sha256:6531ec81bd4ec0f5f0bb60de7ec2b87c939cf35810c355ffba07fd7d31eb0273: waiting |--------------------------------------|
config-sha256:59d8ccfd860dd32dabcd8287c1073f7246e2c8664aeeeb7ec1831029bf1f9a1d: waiting |--------------------------------------|
layer-sha256:ac9208207adaac3a48e54a4dc6b49c69e78c3072d2b3add7efdabf814db2133b: waiting |--------------------------------------|
elapsed: 6.6 s total: 0.0 B (0.0 B/s)九、Containerd管理工具ctr与crictl
containerd的管理工具:
ctr: containerd自带的命令行管理工具,相较docker的命令行工具,其十分不友好,且功能有限
crictl: 由kubernetes官方开发的一个管理支持cri接口的容器运行时的一个通用命令行工具,当containerd作为kubernetes的运行时环境运行时,使用此工具可以较为方便在的kubernetes的worker节点上调试containerd容器
nerdctl: containerd官方新开发的一个containerd的管理工具,完成参照docker的命令行工具开发,功能较为强大;从docker切换至containerd,使用此工具上手较快;目前还未发布正式版
命令对照表
以下为ctr和crictl与docker工具的命令对照表
ctr的基本用法
命名空间管理
containerd有namespace的概念,这一点上跟kubernetes是一样的,其镜像和运行的容器都会属于某一个namespace,默认为default。
以下是namespace的基本操作:
# 1. 列出当前namespace
# ctr namespace ls
NAME LABELS
default
# 2. 创建namespace
# ctr namespace create k8s.io
# ctr namespace list
NAME LABELS
default
k8s.io
# 3. 删除namespace
# ctr namespace rm k8s.io
k8s.io
# 为namespace打标签
# ctr namespace label default project=default
# ctr namespace list
NAME LABELS
default project=default
镜像管理
1.获取镜像
# -n为指定namespace操作,默认即为default
# ctr -n default image pull docker.io/library/nginx:latest
docker.io/library/nginx:latest: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:f3693fe50d5b1df1ecd315d54813a77afd56b0245a404055a946574deb6b34fc: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:b08ecc9f7997452ef24358f3e43b9c66888fadb31f3e5de22fec922975caa75a: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:83500d85111837bbc4a04125fd930f68067e4de851a56d89bd2e03cc3bf7e8ca: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:35c43ace9216212c0f0e546a65eec93fa9fc8e96b25880ee222b7ed2ca1d2151: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:45b42c59be334ecda0daaa139b2f7d310e45c564c5f12263b1b8e68ec9e810ed: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:8acc495f1d914a74439c21bf43c4319672e0f4ba51f9cfafa042a1051ef52671: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:ec3bd7de90d781b1d3e3a55fc40b1ec332b591360fb62dd10b8f28799c2297c1: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:19e2441aeeab2ac2e850795573c62b9aad2c302e126a34ed370ad46ab91e6218: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:f5a38c5f8d4e817a6d0fdc705abc21677c15ad68ab177500e4e34b70e02a201b: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 41.2s total: 50.8 M (1.2 MiB/s)
unpacking linux/amd64 sha256:f3693fe50d5b1df1ecd315d54813a77afd56b0245a404055a946574deb6b34fc...
done2.查看镜像列表
# ctr image ls
REF TYPE DIGEST SIZE PLATFORMS LABELS
docker.io/library/nginx:latest application/vnd.docker.distribution.manifest.list.v2+json sha256:f3693fe50d5b1df1ecd315d54813a77afd56b0245a404055a946574deb6b34fc 51.2 MiB linux/386,linux/amd64,linux/arm/v5,linux/arm/v7,linux/arm64/v8,linux/mips64le,linux/ppc64le,linux/s390x - 3.删除镜像
# ctr i rm docker.io/library/nginx:latest
docker.io/library/nginx:latest容器管理
1.运行容器
containerd运行容器使用ctr run关键字,大多数选项与docker类似,这里有几个注意点:
containerd启动容器,要求镜像必须事先存在,无法像docker一样先检索本地不存在直接拉取;
启动容器时需要指定容器id;
挂载持久卷,除了语法和docker不一样之外,containerd还要求宿主机上被挂载的目录必须提前创建;
下面是一个运行示例:
ctr image pull docker.io/library/busybox:latest
ctr run --rm -t --net-host --privileged --mount type=bind,src=/tmp,dst=/host,options=rbind:rw docker.io/library/busybox:latest test /bin/sh选项说明:
--rm:与docker一样,容器退出时,删除容器
-t:与docker一样,分配一个tty
-d:将容器放入后台运行
--env:向容器中注入环境变量
--privileged:与docker一样,让容器在特权模式下运行
--mount:指定挂载,写法与docker不一样,src表示宿主机的目录,dst为容器中挂载目录
test是为该容器指定的id
再看一个示例:
ctr run -d --env APP_NAME=web01 --env MYSQL=192.168.0.1 --mount type=bind,src=/data/webroot,dst=/usr/share/nginx/html,options=rbind:rw docker.io/library/nginx:latest web01另外我们还可以通过如下方法创建并启动一个容器,但是该方法会将容器放在前台运行:
ctr c create --env APP_NAME=web02 --env MYSQL=192.168.0.1 --mount type=bind,src=/data/webroot,dst=/usr/share/nginx/html,options=rbind:rw docker.io/library/nginx:latest web02
ctr task start web022.查看容器信息
# 查看所有容器
# ctr c list
CONTAINER IMAGE RUNTIME
web01 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
web02 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
# 查看正在运行中的容器
# ctr task list
TASK PID STATUS
web01 105136 RUNNING
# 查看指定容器的进程信息
# ctr task ps web01
PID INFO
105136 &ProcessDetails{ExecID:web01,}
105172 -
# 查看容器的监控指标
# ctr task metric web01
ID TIMESTAMP
web01 2021-02-23 11:35:36.924521801 +0000 UTC
METRIC VALUE
memory.usage_in_bytes 1499136
memory.limit_in_bytes 9223372036854771712
memory.stat.cache 20480
cpuacct.usage 77192788
cpuacct.usage_percpu [39283080 37909708]
pids.current 2
pids.limit 0
# 查看指定容器的详细信息
# ctr c info web01|more
{
"ID": "web01",
"Labels": {
"io.containerd.image.config.stop-signal": "SIGQUIT"
},
"Image": "docker.io/library/nginx:latest",
"Runtime": {
"Name": "io.containerd.runtime.v1.linux",
"Options": null
},
"SnapshotKey": "web01",
"Snapshotter": "overlayfs",
"CreatedAt": "2021-02-23T11:14:30.993274661Z",
"UpdatedAt": "2021-02-23T11:14:30.993274661Z",
"Extensions": null,
"Spec": {
"ociVersion": "1.0.1-dev",
"process": {
"user": {
"uid": 0,
"gid": 0
},
...3.进入容器
# 必须使用--exec-id指定容器的pid
# ctr task exec -t --exec-id 105136 web01 /bin/bash
root@app:/# df -hT
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 40G 21G 20G 52% /
tmpfs tmpfs 64M 0 64M 0% /dev
shm tmpfs 64M 0 64M 0% /dev/shm
tmpfs tmpfs 64M 4.0K 64M 1% /run
/dev/vda1 xfs 40G 21G 20G 52% /usr/share/nginx/html
tmpfs tmpfs 1.9G 0 1.9G 0% /proc/acpi
tmpfs tmpfs 1.9G 0 1.9G 0% /sys/firmware
tmpfs tmpfs 1.9G 0 1.9G 0% /proc/scsi4.其他操作
# 删除容器
ctr c rm web01
# 启动容器
ctr task start web02
# 暂停容器
# ctr task pause web01
# ctr task list
TASK PID STATUS
web01 105136 PAUSED
# 从暂停中恢复
# ctr task resume web01
# ctr task list
TASK PID STATUS
web01 105136 RUNNINGcrictl基本用法
🔍 容器与 Pod 查看
crictl ps列出当前运行的容器。
加上
-a参数可查看所有容器(包括已停止的)示例:
crictl ps -a
crictl pods列出所有 Pod(虽然你的表格里没写,但这是查看 Pod 的核心命令)
🖼️ 镜像管理
crictl images列出本地所有镜像。
加上
-q参数只显示镜像 ID示例:
crictl images nginx:latest
crictl pull <image:tag>从镜像仓库拉取镜像。
示例:
crictl pull docker.io/library/nginx:latest
crictl rmi <image-id>删除一个或多个镜像。
示例:
crictl rmi nginx:latest
crictl rmi --prune清理所有未被使用的镜像,释放磁盘空间。
示例:
crictl rmi --prune
📜 日志与调试
crictl logs <container-id>获取容器的日志。
加上
-f参数可实时跟踪日志输出示例:
crictl logs -f <container-id>
crictl inspect <container-id>查看容器的详细配置和状态信息。
也可以查看 Pod:
crictl inspectp <pod-id>
crictl stats查看容器的资源使用情况(CPU、内存等),类似
docker stats。
⚙️ 容器生命周期管理
crictl create <pod-id> <container-config> [sandbox-config]基于 Pod 和容器配置文件创建一个新容器。
示例:
crictl create <pod-id> container-config.json
crictl start <container-id>启动一个已创建的容器。
crictl stop <container-id>停止一个运行中的容器。
加上
-t 0参数可强制立即停止
crictl rm <container-id>删除一个或多个容器。
加上
-a参数可删除所有容器
crictl exec -it <container-id> <command>在运行的容器中执行命令。
示例:
crictl exec -it <container-id> sh