

从多种部署方式入手,详解 Kubernetes 集群搭建、高可用配置、常用插件安装及集群运维管理,梳理从部署到生产运维的全流程。
使用kube-vip部署kubernetes高可用集群
我们在
kubernetes 1.24单mster集群部署一文中详细说明了使用kubeadm与containerd部署一个单master的集群。事实上在生产环境中基本都是多master部署以确保控制面的可用性。这篇文档的重点是使用kube-vip配置kubernetes master节点的高可用性。
控制面组件包括:
etcd
kube-apiserver
kube-controller-manager
kube-scheduler
其中kube-controller-manager和kube-scheduler是 Kubernetes 集群自己去实现高可用,当有多个节点部署的时候,会自动选择一个作为 Leader 提供服务,不需要我们做额外处理。而etcd和kube-apiserver需要我们去保证高可用。etcd有官方的集群配置,而kube-apiserver属于无状态服务,可以通过为其配置haproxy+keepalived这种常规的负载均衡与vip的方式实现其可用性,示意图如下:
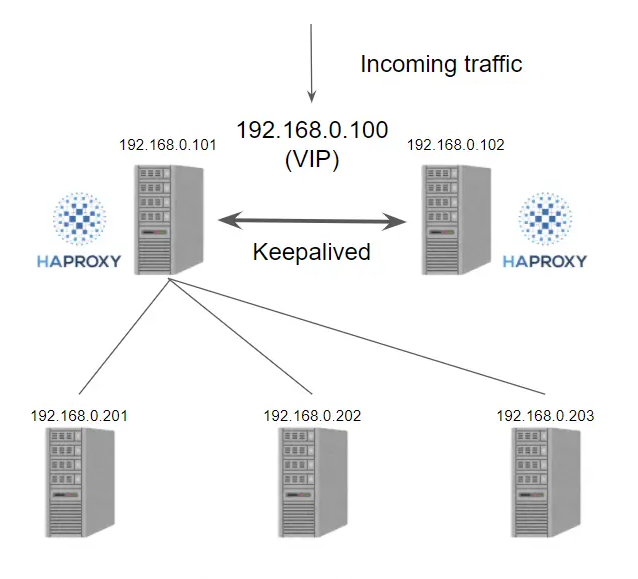
也可以使用较新颖的工具,比如kube-vip。
kube-vip的官方地址: https://kube-vip.io/ kube-vip的代码托管地址: https://github.com/kube-vip/kube-vip
kube-vip与传统的haproxy+ keepalived这种负载均衡方式最大的不同就是其可以在控制平面节点上提供一个 Kubernetes 原生的 HA 负载均衡,这样就不需要额外的节点来部署haproxy+keepalived提供负载均衡服务了。示意图如下:
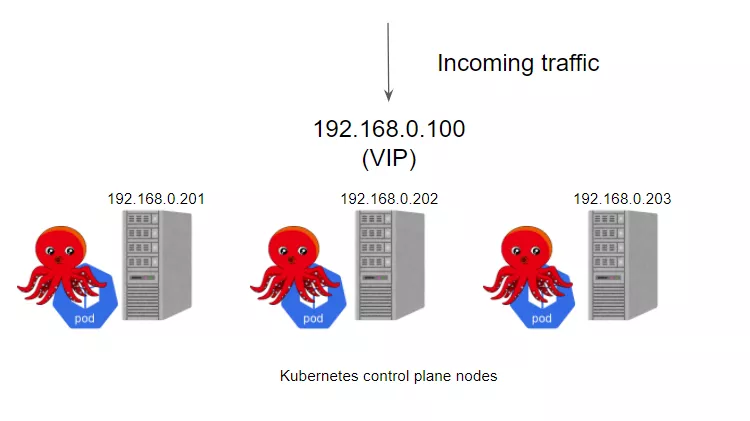
kube-vip 可以以静态 pod的方式 运行在控制面节点上,这些 pod 通过 ARP 会话来识别其他节点,其支持设置模式:
BGP:在这种模式下,所有节点都会绑定一个vip,然后通过bgp协议与物理网络上的三层交换建立邻居实现流量的均衡转发
ARP:在这种模式下,会先出一个leader,leader节点会继承vip并成为集群内负载均衡的leader
这里使用arp模式,在这种模式下,leader将分配vip,并将其绑定到配置中声明的选定接口上。当 Leader 改变时,它将首先撤销 vip,或者在失败的情况下,vip 将直接由下一个当选的 Leader 分配。当 vip 从一个主机移动到另一个主机时,任何使用 vip 的主机将保留以前的 vip <-> MAC 地址映射,直到 ARP 过期(通常是30秒)并检索到一个新的 vip <-> MAC 映射,这可以通过使用无偿的 ARP 广播来优化。
kube-vip 可以被配置为广播一个无偿的 arp(可选),通常会立即通知所有本地主机 vip <-> MAC 地址映射已经改变:
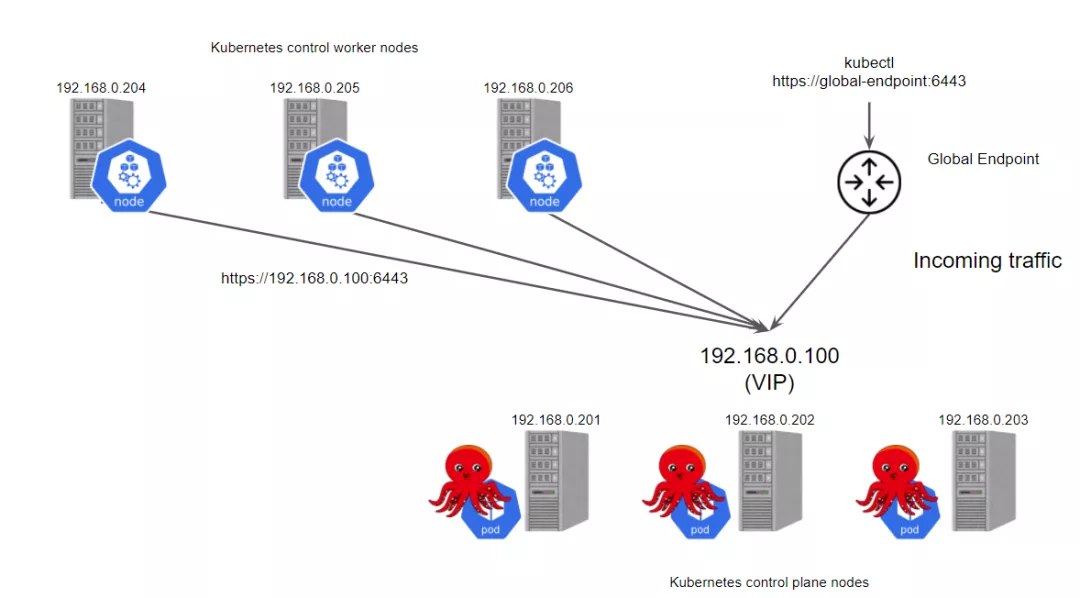
kube-vip除了可以用作kubernetes 控制面的负载均衡,还可以以daemonset的方式部署用以替代kube-proxy
环境说明
配置kube-vip
kube-vip的配置文件需要在安装kubernetes的控制面节点之前准备好,然后在安装控制面时一起安装。
关于安装kubernetes时的环境准备工作已经在kubernetes 1.24单mster集群部署一文中有过详细说明,这里不再赘述。准备好环境之后,可以开始为kube-vip生成相应的部署文件。在这里kube-vip以静态pod的方式部署,所以先在其中一个master节点上生成kube-vip,这里就使用k8s01:
# 创建静态pod目录
mkdir -p /etc/kubernetes/manifests/
# 拉取镜像
ctr image pull docker.io/plndr/kube-vip:v0.3.8
# 使用下面的容器输出静态Pod资源清单
ctr run --rm --net-host docker.io/plndr/kube-vip:v0.3.8 vip \
/kube-vip manifest pod \
--interface eth0 \
--vip 192.168.0.100 \
--controlplane \
--services \
--arp \
--leaderElection | tee /etc/kubernetes/manifests/kube-vip.yaml选项说明:
manifest: 指定生成的配置文件类型,指定为pod则 用于生成静态pod的配置;指定为daemonset用于生成daemonset的配置—interface:指定vip绑定的网卡名称,需要指定master节点内网网卡—vip: 指定要绑定的vip的地址—controlplane:为控制面开启ha—services:开启kubernetes服务—arp:将kube-api启动为arp模式—leaderElection:为集群启用领导者选举机制
生成的kube-vip.yaml内容如下:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: kube-vip
namespace: kube-system
spec:
containers:
- args:
- manager
env:
- name: vip_arp
value: "true"
- name: vip_interface
value: eth0
- name: port
value: "6443"
- name: vip_cidr
value: "32"
- name: cp_enable
value: "true"
- name: cp_namespace
value: kube-system
- name: vip_ddns
value: "false"
- name: svc_enable
value: "true"
- name: vip_leaderelection
value: "true"
- name: vip_leaseduration
value: "5"
- name: vip_renewdeadline
value: "3"
- name: vip_retryperiod
value: "1"
- name: vip_address
value: 192.168.0.100
image: ghcr.io/kube-vip/kube-vip:v0.3.8
imagePullPolicy: Always
name: kube-vip
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
- NET_RAW
- SYS_TIME
volumeMounts:
- mountPath: /etc/kubernetes/admin.conf
name: kubeconfig
hostNetwork: true
volumes:
- hostPath:
path: /etc/kubernetes/admin.conf
name: kubeconfig
status: {}部署控制面
使用如下指令生成部署配置文件:
kubeadm config print init-defaults --component-configs KubeletConfiguration --component-configs KubeProxyConfiguration > kubeadm.yaml修改kubeadm.yaml内容如下:
# cat kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.0.180 # 当前master节点的ip
bindPort: 6443
nodeRegistration:
criSocket: /run/containerd/containerd.sock # 使用 containerd的Unix socket 地址
imagePullPolicy: IfNotPresent
name: k8s01 # master节点的主机名
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
extraArgs:
authorization-mode: Node,RBAC
certSANs: # 添加其他master节点的相关信息
- k8s01
- k8s02
- k8s03
- 127.0.0.1
- localhost
- kubernetes
- kubernetes.default
- kubernetes.default.svc
- kubernetes.default.svc.cluster.local
- 192.168.0.180
- 192.168.0.41
- 192.168.0.241
- 192.168.0.100
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 镜像仓库地址,k8s.gcr.io在国内无法获取镜像
kind: ClusterConfiguration
kubernetesVersion: 1.22.0 # 指定kubernetes的安装版本
controlPlaneEndpoint: 192.168.0.100:6443 # 指定kube-apiserver的vip地址,也可以指定一个外部域名,该域名需要解析至该vip上
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12 # service的网段
podSubnet: 10.244.0.0/16 # pod的网段
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd # 配置cgroup driver为systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging: {}
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true # 证书自动更新
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
bindAddressHardFail: false
clientConnection:
acceptContentTypes: ""
burst: 0
contentType: ""
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
qps: 0
clusterCIDR: ""
configSyncPeriod: 0s
conntrack:
maxPerCore: null
min: null
tcpCloseWaitTimeout: null
tcpEstablishedTimeout: null
detectLocalMode: ""
enableProfiling: false
healthzBindAddress: ""
hostnameOverride: ""
iptables:
masqueradeAll: false
masqueradeBit: null
minSyncPeriod: 0s
syncPeriod: 0s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "ipvs" # kube-proxy的转发模式设置为ipvs
nodePortAddresses: null
oomScoreAdj: null
portRange: ""
showHiddenMetricsForVersion: ""
udpIdleTimeout: 0s
winkernel:
enableDSR: false
networkName: ""
sourceVip: ""重点关注如下变更:
controlPlaneEndpoint: 192.168.0.100:6443 # 指定kube-apiserver的vip地址,也可以指定一个外部域名,该域名需要解析至该vip上
apiServer:
timeoutForControlPlane: 4m0s
extraArgs:
authorization-mode: Node,RBAC
certSANs: # 添加其他master节点的相关信息
- k8s01
- k8s02
- k8s03
- 127.0.0.1
- localhost
- kubernetes
- kubernetes.default
- kubernetes.default.svc
- kubernetes.default.svc.cluster.local
- 192.168.0.180
- 192.168.0.41
- 192.168.0.241
- 192.168.0.100 kubeadm.yaml文件配置完成后,可执行如下指令拉取kubernetes部署所要用到的镜像 :
kubeadm config images pull --config kubeadm.yaml如果出现报错,可以参考kubernetes 1.23单mster集群部署相关操作进行修复。
执行安装:
kubeadm init --upload-certs --config kubeadm.yaml部署成功后会返回类似如下信息:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.0.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1f10cff6e4038f91b1569805e740a0cdfb10ae3001e5ba5343d7eebe9148e2c5 \
--control-plane --certificate-key 281e7bcf740f838aff526f5a6fd2ff8851defec9c152f214c3b847207e557cbe
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1f10cff6e4038f91b1569805e740a0cdfb10ae3001e5ba5343d7eebe9148e2c5配置访问权限:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config配置网络,这里以calico为例:
curl https://docs.projectcalico.org/manifests/calico.yaml -O
kubectl apply -f calico.yaml添加其他控制面
注意,由于coredns:v1.8.4镜像无法正常拉取的问题,建议在其他控制节点上优先把该镜像准备好:
ctr -n k8s.io i pull registry.aliyuncs.com/google_containers/coredns:1.8.4
ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/coredns:1.8.4 registry.aliyuncs.com/google_containers/coredns:v1.8.4使用如下命令添加其他的控制面:
kubeadm join 192.168.0.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1f10cff6e4038f91b1569805e740a0cdfb10ae3001e5ba5343d7eebe9148e2c5 \
--control-plane --certificate-key 281e7bcf740f838aff526f5a6fd2ff8851defec9c152f214c3b847207e557cbe \
--cri-socket /run/containerd/containerd.sock该命令在上面第一个master部署成功后打印,然后我们添加了一个—cri-socket参数以指定使用containerd作为运行时。需要说明的是,该命令中的—certificate-key 的有效期只有2小时,如果超期之后需要执行如下指令重新生成:
# kubeadm init phase upload-certs --upload-certs
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
b3b65d7e6b11803e00f3a141c4e54cb2d9c2c47c8ab3e936088923b92e3dde08此时,我们可以通过如下方式打印完整的添加master的指令:
# kubeadm token create --certificate-key b3b65d7e6b11803e00f3a141c4e54cb2d9c2c47c8ab3e936088923b92e3dde08 --print-join-command
kubeadm join 192.168.0.100:6443 --token iezp4s.jrv9xommiz42slqf --discovery-token-ca-cert-hash sha256:1f10cff6e4038f91b1569805e740a0cdfb10ae3001e5ba5343d7eebe9148e2c5 --control-plane --certificate-key b3b65d7e6b11803e00f3a141c4e54cb2d9c2c47c8ab3e936088923b92e3dde08同样,在真正执行时,不要忘记添加—cri-socket参数。
在添加完控制面节点之后,也需要在这些控制面节点上部署kube-vip,示例如下:
# 创建静态pod目录
mkdir -p /etc/kubernetes/manifests/
# 拉取镜像
ctr image pull docker.io/plndr/kube-vip:v0.3.8
# 使用下面的容器输出静态Pod资源清单
ctr run --rm --net-host docker.io/plndr/kube-vip:v0.3.8 vip \
/kube-vip manifest pod \
--interface eth0 \
--vip 192.168.0.100 \
--controlplane \
--services \
--arp \
--leaderElection | tee /etc/kubernetes/manifests/kube-vip.yaml此时,kubernetes会自动将kube-vip的pod拉起。至此,控制面添加完成。
数据面的添加和kubernetes 1.24单mster集群部署中的操作完全一致,这里不再赘述。
参考: https://mp.weixin.qq.com/s/ypIObV4ARzo-DOY81EDc_Q
Kubernetes使用docker作为运行时
从kubernetes 1.24开始,dockershim已经从kubelet中移除,但因为历史问题docker却不支持kubernetes主推的CRI(容器运行时接口)标准,所以docker不能再作为kubernetes的容器运行时了,即从kubernetesv1.24开始不再使用docker了。
但是如果想继续使用docker的话,可以在kubelet和docker之间加上一个中间层cri-docker。cri-docker是一个支持CRI标准的shim(垫片)。一头通过CRI跟kubelet交互,另一头跟docker api交互,从而间接的实现了kubernetes以docker作为容器运行时。但是这种架构缺点也很明显,调用链更长,效率更低。
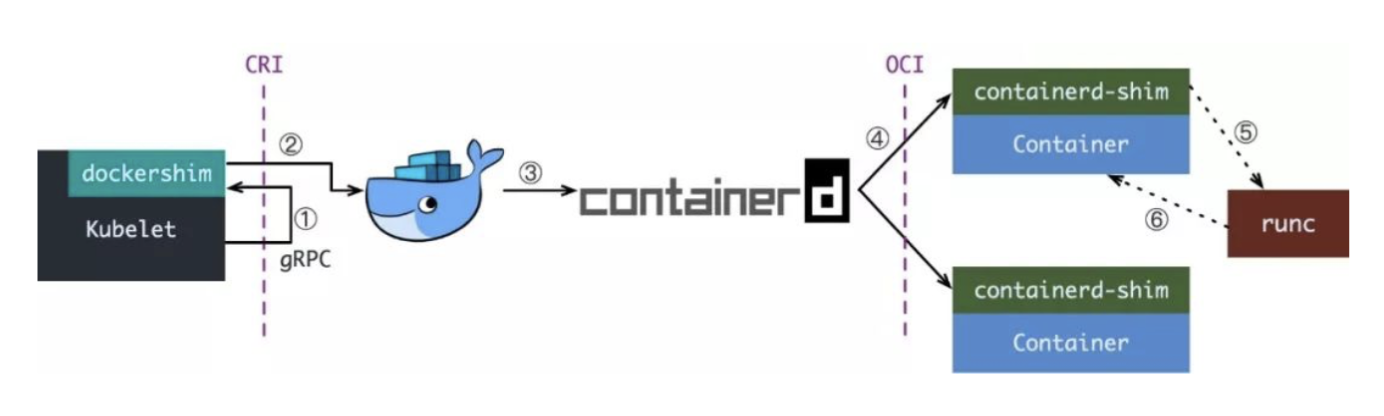
基础环境准备
修改主机名:
# 以一个节点为例
# k8s-master
hostnamectl set-hostname k8s-master --static
# k8s-worker1
hostnamectl set-hostname k8s-worker1 --static
# k8s-worker2
hostnamectl set-hostname k8s-worker2 --static添加/etc/hosts:
# k8s01
e~~cho "192.168.147.128 k8s-master" >> /etc/hosts
# k8s02
echo "192.168.147.129 k8s-worker1" >> /etc/hosts
# k8s03
echo "192.168.147.130 k8s-worker2" >> /etc/hosts~~清空防火墙规则
iptables -F
iptables -t nat -F设置apt源:
cat > /etc/apt/sources.list << EOF
deb https://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
# deb https://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
# deb-src https://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
EOF
apt update -y 配置时间同步:
apt install -y chrony
systemctl enable --now chronyd
chronyc sources 关闭swap:
默认情况下,kubernetes不允许其安装节点开启swap,如果已经开始了swap的节点,建议关闭掉swap
# 临时禁用swap
swapoff -a
# 修改/etc/fstab,将swap挂载注释掉,可确保节点重启后swap仍然禁用
# 可通过如下指令验证swap是否禁用:
free -m # 可以看到swap的值为0
total used free shared buff/cache available
Mem: 7822 514 184 431 7123 6461
Swap: 0 0 0加载内核模块:
cat > /etc/modules-load.d/modules.conf<<EOF
br_netfilter
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
EOF
for i in br_netfilter ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack;do modprobe $i;done这些内核模块主要用于后续将kube-proxy的代理模式从iptables切换至ipvs
修改内核参数:
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
vm.swappiness = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
如果出现sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No Such file or directory这样的错误,说明没有先加载内核模块br_netfilter。
bridge-nf 使 netfilter 可以对 Linux 网桥上的 IPv4/ARP/IPv6 包过滤。比如,设置net.bridge.bridge-nf-call-iptables=1后,二层的网桥在转发包时也会被 iptables的 FORWARD 规则所过滤。常用的选项包括:
net.bridge.bridge-nf-call-arptables:是否在 arptables 的 FORWARD 中过滤网桥的 ARP 包
net.bridge.bridge-nf-call-ip6tables:是否在 ip6tables 链中过滤 IPv6 包
net.bridge.bridge-nf-call-iptables:是否在 iptables 链中过滤 IPv4 包
net.bridge.bridge-nf-filter-vlan-tagged:是否在 iptables/arptables 中过滤打了 vlan 标签的包。
安装docker
在所有节点安装
# 安装docker
yum install -y docker-ce
# 生成docker配置文件
{
"registry-mirrors": ["https://o0o4czij.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"data-root": "/data/docker",
"log-level": "info",
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.size=30G"
],
"log-opts": {
"max-size": "100m",
"max-file": "10"
},
"live-restore": true
}
# 启动docker
systemctl enable docker --now安装cri-docker
在所有节点安装
cri-docker的代码托管地址: Mirantis/cri-dockerd (github.com)
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/software/kubernetes/cri-dockerd-0.3.10.amd64.tgz
tar xf cri-dockerd-0.3.10.amd64.tgz
cp cri-dockerd/cri-dockerd /usr/bin/
cri-docker的启动文件有两个:
cri-docker.service
cri-docker.socket
这两个文件可以在cir-docker的源代码目录packaging/systemd中找到,但是cri-docker.service的启动项还要做如下修改:
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9说明:
在kubernetes中使用,必须要指定—network-plugin=cni,在0.2.5及更高版本的cir-docker中,此为默认值
通过指定—pod-infra-container-image指定pause镜像地址
启动cri-docker并设置开机自启:
systemctl daemon-reload
systemctl enable cri-docker.service
systemctl enable --now cri-docker.socket
systemctl start cri-docker安装kubernetes
安装kubeadm、kubelet、kubectl:
apt-get update && apt-get install -y apt-transport-https && \
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add - && \
cat > /etc/apt/sources.list.d/kubernetes.list<<EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt update -y && \
apt-cache madison kubeadm && \
apt install -y kubelet=1.28.2-00 kubeadm=1.28.2-00 kubectl=1.28.2-00 && \
systemctl enable kubelet通过如下指令创建默认的kubeadm.yaml文件:
kubeadm config print init-defaults > kubeadm.yaml修改kubeadm.yaml文件如下:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 172.26.159.93 # 设置master节点的ip地址
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock # 设置cri-docker的连接套接字
imagePullPolicy: IfNotPresent
name: 172.26.159.93 # 指定master的主机名
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 指定下载master组件镜像的镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: 1.24.3
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 指定pod ip的网段
scheduler: {}执行部署:
kubeadm init --config=kubeadm.yaml添加节点配置如下:
kubeadm join 192.168.0.180:6443 --token cjb89t.io9c7dev0huiyuwk --discovery-token-ca-cert-hash sha256:e5280f1d03a526e2cbf803931aa0601a46b76f53fb9f8beb1255deb59dbd17e5 --node-name 10.64.132.5 --cri-socket unix:///var/run/cri-dockerd.sock附录
指定—pod-infra-container-image配置项
如果不通过—pod-infra-container-image指定pause镜像地址,则会抛出如下异常:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 12s default-scheduler Successfully assigned kube-system/calico-node-4vssv to 10.64.132.5
Warning FailedCreatePodSandBox 8s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.1": Error response from daemon: Get "https://k8s.gcr.io/v2/": dial tcp 108.177.97.82:443: connect: connection timed out参考:
Ubuntu 22.04部署kubernetes 1.28
环境准备
准备工作需要在所有节点上操作,包含的过程如下:
配置主机名
添加/etc/hosts
清空防火墙
设置apt源
配置时间同步
关闭swap
配置内核参数
加载ip_vs内核模块
安装Containerd
安装kubelet、kubectl、kubeadm
修改主机名:
# 以一个节点为例
# k8s-master
hostnamectl set-hostname k8s-master --static
# k8s-worker1
hostnamectl set-hostname k8s-worker1 --static
# k8s-worker2
hostnamectl set-hostname k8s-worker2 --static添加/etc/hosts:
# k8s01
echo "192.168.147.128 k8s-master" >> /etc/hosts
# k8s02
echo "192.168.147.129 k8s-worker1" >> /etc/hosts
# k8s03
echo "192.168.147.130 k8s-worker2" >> /etc/hosts清空防火墙规则
iptables -F
iptables -t nat -F设置apt源:
sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list
apt update -y 配置时间同步:
apt install -y chrony
systemctl enable --now chronyd
chronyc sources 关闭swap:
默认情况下,kubernetes不允许其安装节点开启swap,如果已经开始了swap的节点,建议关闭掉swap
# 临时禁用swap
swapoff -a
# 修改/etc/fstab,将swap挂载注释掉,可确保节点重启后swap仍然禁用
# 可通过如下指令验证swap是否禁用:
free -m # 可以看到swap的值为0
total used free shared buff/cache available
Mem: 7822 514 184 431 7123 6461
Swap: 0 0 0
加载内核模块:
cat > /etc/modules-load.d/modules.conf<<EOF
br_netfilter
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
EOF
for i in br_netfilter ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack;do modprobe $i;done
这些内核模块主要用于后续将kube-proxy的代理模式从iptables切换至ipvs
修改内核参数:
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
vm.swappiness = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
如果出现sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No Such file or directory这样的错误,说明没有先加载内核模块br_netfilter。
bridge-nf 使 netfilter 可以对 Linux 网桥上的 IPv4/ARP/IPv6 包过滤。比如,设置net.bridge.bridge-nf-call-iptables=1后,二层的网桥在转发包时也会被 iptables的 FORWARD 规则所过滤。常用的选项包括:
net.bridge.bridge-nf-call-arptables:是否在 arptables 的 FORWARD 中过滤网桥的 ARP 包
net.bridge.bridge-nf-call-ip6tables:是否在 ip6tables 链中过滤 IPv6 包
net.bridge.bridge-nf-call-iptables:是否在 iptables 链中过滤 IPv4 包
net.bridge.bridge-nf-filter-vlan-tagged:是否在 iptables/arptables 中过滤打了 vlan 标签的包。
安装containerd:
apt-get update -y && \
apt-get -y install apt-transport-https ca-certificates curl software-properties-common && \
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - && \
add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" && \
apt-get -y update && \
apt-get -y install containerd.io
# 生成containerd的配置文件
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
# 修改/etc/containerd.config.toml配置文件以下内容:
......
[plugins]
......
[plugins."io.containerd.grpc.v1.cri"]
...
#sandbox_image = "k8s.gcr.io/pause:3.6"
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
#对于使用 systemd 作为 init system 的 Linux 的发行版,使用 systemd 作为容器的 cgroup driver 可以确保节点在资源紧张的情况更加稳定
SystemdCgroup = true
......
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
... 配置镜像代理:
mkdir -p /etc/containerd/certs.d/{docker.io,k8s.gcr.io}
# docker.io/hosts.yaml
server = "https://registry-1.docker.io"
[host."https://docker.m.daocloud.io"]
capabilities = ["pull", "resolve", "push"]
#skip_verify = true
# k8s.gcr.io/hosts.yaml
server = "https://k8s.gcr.io"
[host."https://registry.aliyuncs.com/google_containers"]
capabilities = ["pull", "resolve", "push"]
#skip_verify = true
安装kubeadm、kubelet、kubectl:
apt-get update && apt-get install -y apt-transport-https && \
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
cat > /etc/apt/sources.list.d/kubernetes.list<<EOF
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/kubernetes/core:/stable:/v1.28/deb/ /
EOF
apt update -y && \
apt-cache madison kubeadm && \
apt install -y kubelet=1.28.2-00 kubeadm=1.28.2-00 kubectl=1.28.2-00 && \
systemctl enable kubelet
部署master
部署master,只需要在master节点上配置,包含的过程如下:
生成kubeadm.yaml文件
编辑kubeadm.yaml文件
根据配置的kubeadm.yaml文件部署master
通过如下指令创建默认的kubeadm.yaml文件:
kubeadm config print init-defaults > kubeadm.yaml修改kubeadm.yaml文件如下:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.147.128 # 设置master节点的ip地址
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock # 设置containerd的连接套接字
imagePullPolicy: IfNotPresent
name: k8s-master # 指定master的主机名
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 指定下载master组件镜像的镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: 1.28.1
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 指定pod ip的网段
scheduler: {}拉取镜像:
kubeadm config images pull --config kubeadm.yaml如果抛出如下异常:
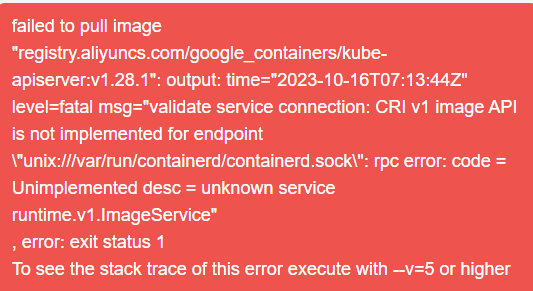
解决方法如下:
mkdir /sys/fs/cgroup/systemd -p
mount -t cgroup -o none,name=systemd cgroup /sys/fs/cgroup/systemd之后重启containerd即可:
systemctl restart containerd安装master节点:
kubeadm init --upload-certs --config kubeadm.yaml此时如下看到类似如下输出即代表master安装完成:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.147.128:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:cad3fa778559b724dff47bb1ad427bd39d97dd76e934b9467507a2eb990a50c7配置访问集群:
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -u) $HOME/.kube/config配置网络
在master完成部署之后,发现两个问题:
master节点一直notready
coredns pod一直pending
其实这两个问题都是因为还没有安装网络插件导致的,kubernetes支持众多的网络插件,详情可参考这里: https://kubernetes.io/docs/concepts/cluster-administration/addons/
我们这里使用calico网络插件,安装如下:
curl https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/cka/calico-v3.26.3.yaml -O
kubectl apply -f calico.yaml安装网络插件,也只需要在master节点上操作即可
部署完成后,可以通过如下指令验证组件是否正常:
检查master组件是否正常:
# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-58497c65d5-f48xk 1/1 Running 0 94s
calico-node-nh4xb 1/1 Running 0 94s
coredns-7f6cbbb7b8-7r558 1/1 Running 0 4m45s
coredns-7f6cbbb7b8-vr58g 1/1 Running 0 4m45s
etcd-192.168.0.180 1/1 Running 0 4m54s
kube-apiserver-192.168.0.180 1/1 Running 0 4m54s
kube-controller-manager-192.168.0.180 1/1 Running 0 5m
kube-proxy-wx49q 1/1 Running 0 4m45s
kube-scheduler-192.168.0.180 1/1 Running 0 4m54s查看节点状态:
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.0.180 Ready control-plane,master 4m59s v1.22.0添加worker节点
在master节点上,当master部署成功时,会返回类似如下信息:
kubeadm join 192.168.0.180:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:cad3fa778559b724dff47bb1ad427bd39d97dd76e934b9467507a2eb990a50c7 --node-name 192.168.0.41即可完成节点的添加
需要说明的是,以上指令中的token有效期只有24小时,当token失效以后,可以使用
kubeadm token create --print-join-command生成新的添加节点指令
—node-name用于指定要添加的节点的名称
配置ingress
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/cka/ingress-nginx-v1.9.3.yaml
kubectl apply -f ingress-nginx-v1.9.3.yaml配置metrics-server
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/cka/metrics-server-v0.6.4.yaml
kubectl apply -f metrics-server-v0.6.4.yaml配置nfs-csi
安装nfs:
apt install -y nfs-kernel-server
mkdir -p /data
chmod 777 /data -R
echo "/data *(rw,sync,no_root_squash)" >> /etc/exports
systemctl enable nfs-server
systemctl restart nfs-server
# 验证
showmount -e 192.168.147.128安装nfs-csi:
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/cka/csi-driver-nfs-4.4.0.tar.gz
tar xf csi-driver-nfs-4.4.0.tar.gz
cd csi-driver-nfs-4.4.0
kubectl apply -f v4.4.0配置storage:
# nfs-csi.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: "true"
name: csi-hostpath-sc
mountOptions:
- hard
- nfsvers=4.0
parameters:
server: 192.168.147.128
share: /data
provisioner: nfs.csi.k8s.io
reclaimPolicy: Delete
volumeBindingMode: Immediate
# 部署
kubectl apply -f nfs-csi.yaml测试创建pvc:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 8Gi
storageClassName: csi-hostpath-sc使用pvc:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: busybox
name: busybox
spec:
replicas: 1
selector:
matchLabels:
app: busybox
strategy: {}
template:
metadata:
labels:
app: busybox
spec:
volumes:
- name: test
persistentVolumeClaim:
claimName: myclaim
containers:
- image: busybox:1.28
name: busybox
volumeMounts:
- name: test
mountPath: /data
command:
- /bin/sh
- -c
- "sleep 3600"
resources: {}附录
在执行kubeadm init —config yaml时出错,kubelet 抛出如下异常:
root@k8s01:~# journalctl -xe -u kubelet
1365 12377 kubelet_node_status.go:70] "Attempting to register node" node="k8s01"
1630 12377 kubelet_node_status.go:92] "Unable to register node with API server" err="Post \"https://172.26.>3821 12377 kubelet.go:2424] "Error getting node" err="node \"k8s01\" not found"
5521 12377 reflector.go:324] vendor/k8s.io/client-go/informers/factory.go:134: failed to list *v1.Service: >5569 12377 reflector.go:138] vendor/k8s.io/client-go/informers/factory.go:134: Failed to watch *v1.Service:>4782 12377 kubelet.go:2424] "Error getting node" err="node \"k8s01\" not found"进一步检查 containerd的日志,有如下异常:
box for &PodSandboxMetadata{Name:kube-controller-manager-k8s01,Uid:442564a9a3387a3cfb3eff3a22c04e1f,Namespace>box for &PodSandboxMetadata{Name:kube-scheduler-k8s01,Uid:233150635540b26cd6ef074fe008014c,Namespace:kube-sys>t host" error="failed to do request: Head \"https://k8s.gcr.io/v2/pause/manifests/3.7\": dial tcp 142.250.157>dbox for &PodSandboxMetadata{Name:etcd-k8s01,Uid:7015b34aae829f2c642db4efe16bdb75,Namespace:kube-system,Attem>t host" error="failed to do request: Head \"https://k8s.gcr.io/v2/pause/manifests/3.7\": dial tcp 142.250.157>dbox for &PodSandboxMetadata{Name:kube-apiserver-k8s01,Uid:11ebe35165cc34f039475769cced894b,Namespace:kube-sy>t host" error="failed to do request: Head \"https://k8s.gcr.io/v2/pause/manifests/3.7\": dial tcp 142.250.157>dbox for &PodSandboxMetadata{Name:kube-controller-manager-k8s01,Uid:442564a9a3387a3cfb3eff3a22c04e1f,Namespac>t host" error="failed to do request: Head \"https://k8s.gcr.io/v2/pause/manifests/3.7\": dial tcp 142.250.157>dbox for &PodSandboxMetadata{Name:kube-scheduler-k8s01,Uid:233150635540b26cd6ef074fe008014c,Namespace:kube-sy err="rpc error: code = Unknown desc = failed to create containerd task: cgroups: cgroup mountpoint does not exist: unknown"解决办法:
mkdir /sys/fs/cgroup/systemd
mount -t cgroup -o none,name=systemd cgroup /sys/fs/cgroup/systemd使用Sealos部署Kubernetes
sealos官方文档地址: https://sealos.io/zh-Hans/docs/Intro sealos代码托管地址: https://github.com/labring/sealos
使用sealos安装kubernetes可参考: https://sealos.io/zh-Hans/docs/self-hosting/lifecycle-management/quick-start/deploy-kubernetes
sealos不同的版本对应着可以安装的kubernetes的版本
Kubernetes部署管理
添加node节点
执行如下指令生成添加node节点的命令:
kubeadm token create --print-join-command返回结果类似如下:
kubeadm join 192.168.0.180:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:cad3fa778559b724dff47bb1ad427bd39d97dd76e934b9467507a2eb990a50c7在要添加的节点上直接执行上面的命令即可。
添加master节点
在现有master节点上用于生成新master加入使用的证书:
kubeadm init phase upload-certs --upload-certs返回内容大致如下:
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
e799a655f667fc327ab8c91f4f2541b57b96d2693ab5af96314ebddea7a68526之后使用添加node节点时返回的命令中得到的token和discovery-token-ca-cert-hash拼接成添加master的指令:
kubeadm join 192.168.0.180:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:cad3fa778559b724dff47bb1ad427bd39d97dd76e934b9467507a2eb990a50c7 --control-plane --certificate-key e799a655f667fc327ab8c91f4f2541b57b96d2693ab5af96314ebddea7a68526使用该指令在新master节点上执行即可。
删除节点
在kubernetes中,删除master和删除worker节点的操作是一样的:
# 将节点设置为不可调度并驱逐上面的pod
kubectl drain <node> --ignore-daemonsets
kubectl delete node <node>升级集群
删除集群
更新集群证书
Kubernetes常用插件安装
这里统一使用helm安装相关插件,所以需要先安装好helm:
wget https://breezey-public.oss-cn-zhangjiakou.aliyuncs.com/softwares/linux/kubernetes/helm-v3.6.3-linux-amd64.tar.gz
tar xf helm-v3.6.3-linux-amd64.tar.gz
cd helm-v3.6.3-linux-amd64
cp helm /usr/bin/常用add-ons:
ingress
metrics-server
keda
node-problem-detector
openkruise
metricbeat
dashboard
prometheus-operator
ingress
ingress的github地址: github.com/kubernetes/ingress-nginx
部署:
# 添加helm源
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
# 获取安装包
helm fetch ingress-nginx/ingress-nginx
tar xf ingress-nginx-4.0.6.tgz
cd ingress-nginx修改values.yaml内容如下:
controller:
name: controller
image:
registry: registry.cn-zhangjiakou.aliyuncs.com
image: breezey/ingress-nginx
#digest: sha256:545cff00370f28363dad31e3b59a94ba377854d3a11f18988f5f9e56841ef9ef
tag: "v1.0.4"
...
config:
allow-backend-server-header: "true"
enable-underscores-in-headers: "true"
generate-request-id: "true"
ignore-invalid-headers: "true"
keep-alive: "30"
keep-alive-requests: "50000"
log-format-upstream: $remote_addr - [$remote_addr] - $remote_user [$time_local]
"$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length
$request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length
$upstream_response_time $upstream_status $req_id $host
max-worker-connections: "65536"
proxy-body-size: 100m
proxy-connect-timeout: "5"
proxy-next-upstream: "off"
proxy-read-timeout: "5"
proxy-send-timeout: "5"
#proxy-set-headers: ingress-nginx/custom-headers
reuse-port: "true"
server-tokens: "false"
ssl-redirect: "false"
upstream-keepalive-connections: "200"
upstream-keepalive-timeout: "900"
use-forwarded-headers: "true"
worker-cpu-affinity: auto
worker-processes: auto
...
replicaCount: 2
ingressClassResource:
name: nginx
enabled: true
default: true
controllerValue: "k8s.io/ingress-nginx"
...
tolerations:
- key: ingressClass
operator: Equal
value: nginx
effect: NoSchedule
...
nodeSelector:
kubernetes.io/os: linux
ingressClass: nginx
...
admissionWebhooks:
...
patch:
enabled: true
image:
registry: dyhub.douyucdn.cn
image: library/kube-webhook-certgen
tag: v1.1.1
#digest: sha256:64d8c73dca984af206adf9d6d7e46aa550362b1d7a01f3a0a91b20cc67868660
pullPolicy: IfNotPresent
...
defaultBackend:
##
enabled: true
name: defaultbackend
image:
registry: registry.cn-zhangjiakou.aliyuncs.com
image: breezey/defaultbackend-amd64执行安装:
kubectl create ns ingress-nginx
helm install -n ingress-nginx ingress-nginx ./metrics-server
metrics-server用于在集群内部向kube-apiserver暴露集群指标。
代码托管地址: https://github.com/kubernetes-sigs/metrics-server
部署
# 下载chart包
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/metrics-server-helm-chart-3.12.2/metrics-server-3.12.2.tgz
# 解压
tar xf metrics-server-3.12.2.tgz
cd metrics-server修改values.yaml内容如下:
image:
repository: registry.k8s.io/metrics-server/metrics-server
# Overrides the image tag whose default is v{{ .Chart.AppVersion }}
tag: "v0.7.2"
...
defaultArgs:
- --cert-dir=/tmp
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls=true
...
tolerations:
- operator: Exists
执行安装:
helm upgrade -i -n kube-system metrics-server ./验证:
[root@cka-master metrics-server]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
192.168.0.93 169m 8% 1467Mi 39%
cka-node1 138m 6% 899Mi 24%metricbeat
metricbeat是ELastic的beats家族成员,可用于采集相关监控指标及事件。这里主要用作收集kubernetes相关事件。另一个类似的组件为阿里云开源的kube-eventer,是一个用于采集pod相关事件的收集器,它可以将相关的事件发送至kafka,mysql,es等sink
metricbeat的部署文档参考: https://www.elastic.co/guide/en/beats/metricbeat/current/running-on-kubernetes.html
kube-eventer的代码仓库地址: https://github.com/AliyunContainerService/kube-eventer
1. 部署kube-state-metrics
需要说明的是,metricbeat采集kubernetes相关事件,需要依赖kube-state-metrics,所以,需要先安装这个组件。
helm repo add azure-marketplace https://marketplace.azurecr.io/helm/v1/repo
helm show values azure-marketplace/kube-state-metrics > kube-state-metrics.yaml
修改kube-state-metrics.yaml内容如下:
global:
imageRegistry: registry.cn-zhangjiakou.aliyuncs.com
image:
registry: registry.cn-zhangjiakou.aliyuncs.com
repository: breezey/kube-state-metrics
tag: 1.9.7-debian-10-r143执行部署:
helm install -n kube-system kube-state-metrics azure-marketplace/kube-state-metrics -f kube-state-metrics.yaml2. 部署metricbeat
curl -L -O https://raw.githubusercontent.com/elastic/beats/7.10/deploy/kubernetes/metricbeat-kubernetes.yaml
删除掉daemonset相关配置,因为那些配置用于采集系统及kubernetes的监控指标,而我们这里只采集事件。
然后修改ConfigMap内容如下
...
fields:
cluster: k8s-test-hwcloud
metricbeat.config.modules:
# Mounted `metricbeat-daemonset-modules` configmap:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: true
...
output.kafka:
hosts: ["10.32.99.62:9092","10.32.99.142:9092","10.32.99.143:9092","10.32.99.145:9092","10.32.99.146:9092","10.32.99.147:9092","10.32.99.148:9092"]
topic: 'ops_k8s_event_log'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
...
kubernetes.yml: |-
- module: kubernetes
metricsets:
# Uncomment this to get k8s events:
- event
period: 10s
host: ${NODE_NAME}
hosts: ["kube-state-metrics:8080"]
...执行部署:
kubectl apply -f metricbeat-kubernetes.yamldashboard
为kubernetes提供web-ui
dashboard的github仓库地址:https://github.com/kubernetes/dashboard
安装:
# 添加helm源
helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
helm repo update此时,即可通过浏览器访问web端,端口为32443:
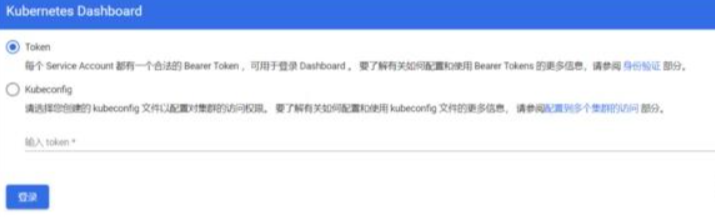
可以看到出现如上图画面,需要我们输入一个kubeconfig文件或者一个token。事实上在安装dashboard时,也为我们默认创建好了一个serviceaccount,为kubernetes-dashboard,并为其生成好了token,我们可以通过如下指令获取该sa的token:
kubectl describe secret -n kubernetes-dashboard $(kubectl get secret -n kubernetes-dashboard |grep kubernetes-dashboard-token | awk '{print $1}') |grep token | awk '{print $2}'
eyJhbGciOiJSUzI1NiIsImtpZCI6IkUtYTBrbU44TlhMUjhYWXU0VDZFV1JlX2NQZ0QxV0dPRjBNUHhCbUNGRzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291eeeeeeLWRhc2hib2FyZC10b2tlbi1rbXBuMiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFxxxxxxxxxxxxxxxxxxxxxxxGZmZmYxLWJhOTAtNDU5Ni1hMzgxLTRhNDk5NzMzYWI0YiIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDprdWJlcm5ldGVzLWRhc2hib2FyZCJ9.UwAsemOra-EGl2OzKc3lur8Wtg5adqadulxH7djFpmpWmDj1b8n1YFiX-AwZKSbv_jMZd-mvyyyyyyyyyyyyyyyMYLyVub98kurq0eSWbJdzvzCvBTXwYHl4m0RdQKzx9IwZznzWyk2E5kLYd4QHaydCw7vH26by4cZmsqbRkTsU6_0oJIs0YF0YbCqZKbVhrSVPp2Fw5IyVP-ue27MjaXNCSSNxLX7GNfK1W1E68CrdbX5qqz0-Ma72EclidSxgs17T34p9mnRq1-aQ3ji8bZwvhxuTtCw2DkeU7DbKfzXvJw9ENBB-A0fN4bewP6Og07Q通过该token登入集群以后,发现很多namespace包括一些其他的资源都没有足够的权限查看。这是因为默认我们使用的这个帐户只有有限的权限。我们可以通过对该sa授予cluster-admin权限来解决这个问题:
修改ClusterRoleBinding资源内容如下:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard重新创建clusterrolebinding:
kubectl delete clusterrolebinding kubernetes-dashboard -n kubernetes-dashboard
kubectl apply -f ./recommended.yaml此时,kubernetes-dashboard相关配置即完成。
KEDA
keda全称为kubernetes event driven autoscaler,为kubernetes提供基于事件驱动的自动伸缩
github仓库地址: https://github.com/kedacore/keda
官方文档地址: https://keda.sh
安装:
# 添加helm源
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
# 获取配置文件
helm show values kedacore/keda > keda.yaml
修改 keda.yaml
image:
keda:
repository: registry.cn-zhangjiakou.aliyuncs.com/breezey/keda
tag: 2.4.0
metricsApiServer:
repository: registry.cn-zhangjiakou.aliyuncs.com/breezey/keda-metrics-apiserver
tag: 2.4.0
pullPolicy: Always执行安装:
kubectl create ns keda
helm install keda -n keda ./openkruise
openKruise的官方代码库地址: https://github.com/openkruise/kruise
官方文档地址: https://openkruise.io/
安装:
helm repo add openkruise https://openkruise.github.io/charts/
helm repo update
helm install kruise openkruise/kruise -n kube-system --version 0.10.0这里也可以直接使用阿里云官方的chart仓库: helm repo add incubator https://aliacs-k8s-cn-beijing.oss-cn-beijing.aliyuncs.com/app/charts-incubator
node-problem-detect
安装:
helm repo add deliveryhero https://charts.deliveryhero.io/
helm repo update
helm show values deliveryhero/node-problem-detector --version 2.0.9 > node-problem-detector.yaml
修改node-problem-detector.yaml内容如下:
image:
repository: registry.cn-zhangjiakou.aliyuncs.com/breezey/node-problem-detector
tag: v0.8.10
pullPolicy: IfNotPresent安装:
helm install -n kube-system node-problem-detect deliveryhero/node-problem-detector --version 2.0.9 -f ./node-problem-detector.yaml Kind快速部署单机kubernetes
官方文档:kind (k8s.io) 项目地址: kubernetes-sigs/kind: Kubernetes IN Docker - local clusters for testing Kubernetes (github.com)
部署
安装docker:
下载kind:
[ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.26.0/kind-linux-amd64执行部署:
./kind create cluster --image=kindest/node:v1.32.0部署完成后,执行如下命令可以查看到当前集群状态:
kubectl cluster-info --context kind-kind附录
参考: Kubernetes教程(十五)---使用 kind 在本地快速部署一个 k8s集群 - (lixueduan.com)
Cluster-API
cluster-api文档地址:https://cluster-api.sigs.k8s.io/introduction
cluster-api代码托管地址:kubernetes-sigs/cluster-api: Home for Cluster API, a subproject of sig-cluster-lifecycle (github.com)
本文档撰写时cluster-api版本为1.7.4
Cluster API原理
Cluster API由Kubernetes特别兴趣小组Cluster Lifecycle发起,旨在提供K8S即服务能力。用Kubernetes的能力管理Kubernetes,用Kubernetes的方式提供Kubernetes集群生命周期管理,并且支持管理集群相关的基础设施(虚拟机、网络、负载均衡器、VPC 等)。通过以上种种方式,让K8S基础设施的生命周期管理也变得非常云原生化。
Kubernetes集群依赖于几个组件协同工作才能正常运行,以下是kubeadm部署集群的流程:
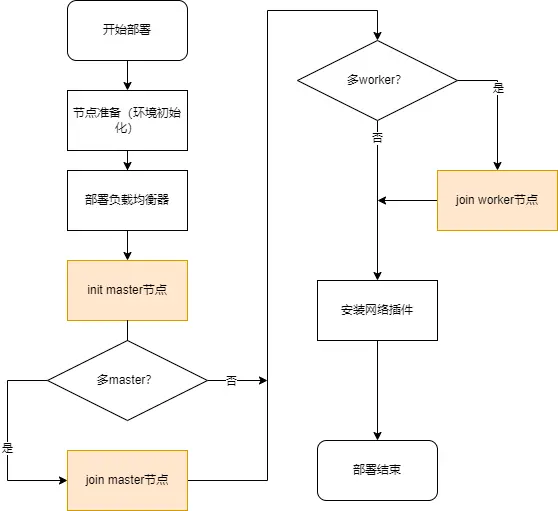
kubeadm的出现很大程度上降低了这些组件部署的复杂度,并且对集群重复部署的问题也给出了一个很好的答案,不过正如上图所示,几乎每一步都需要人工手动操作,部署人员辗转多台服务器之间重复着相同的操作。同时面对日益增长的集群环境,kubeadm并没有解决如何对自己已部署的集群进行管理。
除此之外还包括以下问题:
如何针对异构集群一致地配置机器、负载均衡器、VPC 等?
如何自动化管理集群生命周期,包括升级和删除集群?
如何扩展并管理任意数量的集群?
而Cluster API提供了声明式的集群管理方式。通过申明式的构建具有Kubernetes风格的API,完成诸如集群自动创建、配置和管理等功能。同时支持您使用不同的基础设施提供商以及引导程序提供商来构建管理您的集群。
Cluster API架构
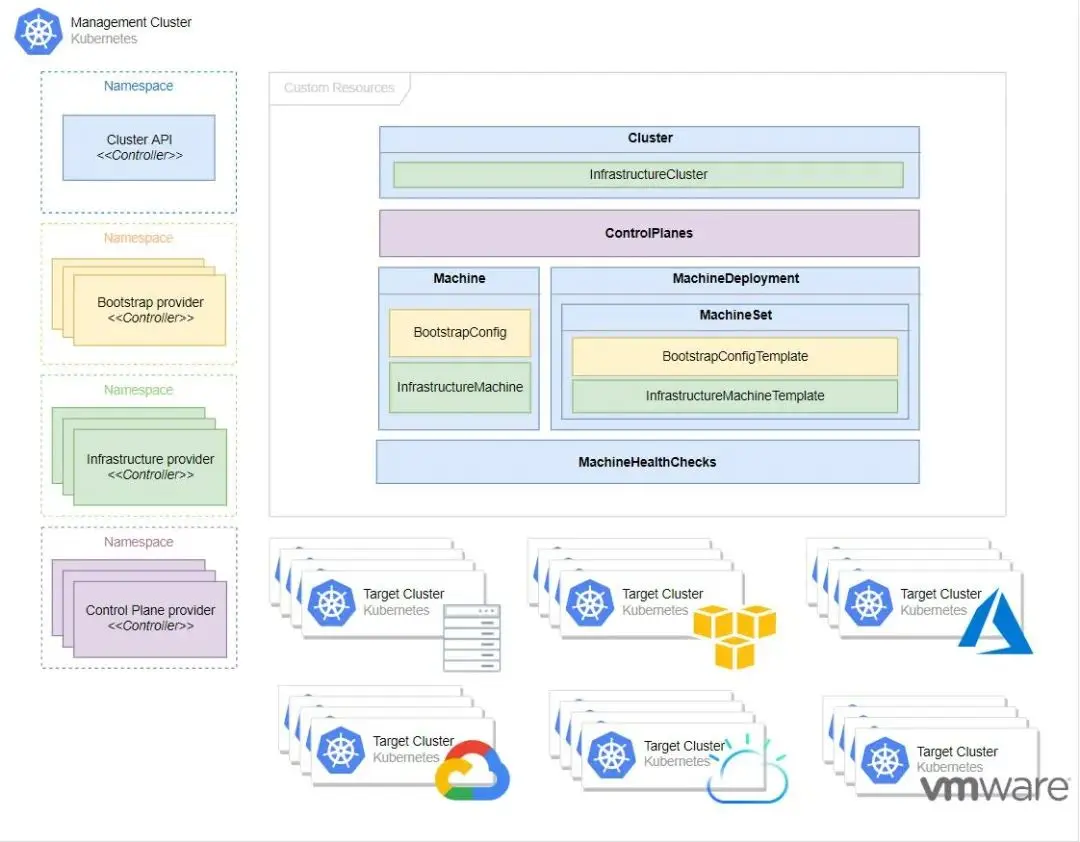
Management Cluster
Cluster API工作的集群,在该集群上运行着一个或多个基础设施提供程序,并保存着Cluster API相关的CRD资源。是负责管理工作集群生命周期的集群。
Target Cluster
工作集群,由管理集群创建并管理其生命周期。
Infrastructure provider
基础设施提供商,工作集群基础设施的实际提供者(如 AWS、Azure 和 Google等),由各大厂商实现,但需要遵循Cluster API的规范去实现相应的接口和逻辑。
Control plane provider
控制平面提供者,负责Target Cluster控制平面的节点生成,Cluster API 默认使用kubeadm引导控制平面。对于不同厂商可实现适配自己的控制平面引导程序。
Bootstrap Provider
引导程序提供者,负责集群证书生成,初始化控制平面,并控制其他节点(控制平面和工作节点)加入集群。Cluster API默认使用基于 kubeadm 的引导程序。对于不同厂商可实现适配自己的节点引导程序。
Custom Resources
自定义资源,Cluster API 提供并依赖于几个自定义资源:
Machine
MachineDeployment
MachineSet
Cluster
附录
参考: https://segmentfault.com/a/1190000042550707
cluster-api部署
安装
这里使用kubevirt作为provider以提供安装:
clusterctl init --infrastructure kubevirt在执行安装后,输出如下:
Fetching providers
Installing cert-manager Version="v1.15.1"
Waiting for cert-manager to be available...
Installing Provider="cluster-api" Version="v1.7.4" TargetNamespace="capi-system"
Installing Provider="bootstrap-kubeadm" Version="v1.7.4" TargetNamespace="capi-kubeadm-bootstrap-system"
Installing Provider="control-plane-kubeadm" Version="v1.7.4" TargetNamespace="capi-kubeadm-control-plane-system"
Installing Provider="infrastructure-kubevirt" Version="v0.1.9" TargetNamespace="capk-system"
Your management cluster has been initialized successfully!
You can now create your first workload cluster by running the following:
clusterctl generate cluster [name] --kubernetes-version [version] | kubectl apply -f -
可以看到安装了如下几个组件:
cluster-api:又被称之为Cluster API manager,用于管理cluster核心资源
bootstrap-kubeadm:Bootstrap provider manager的一种,用于管理资源以生成将Machine转变为Kubernetes节点的数据
control-plane-kubeadm:用于通过kubeadm管理工作集群的控制面
infrastructure-kubevirt:Infrastructure provider manager的一种,用于管理提供运行集群所需基础架构的资源
可以通过如下命令看到所有这些组件的部署yaml的来源仓库:
clusterctl config repositories需要说明的是,以上部署操作,会在kubernetes中生成以下五个命名空间:
cert-manager:用于部署cert-manager,为cluster-api相关组件自动签发证书
capi-system:用于部署capi-controller-manager组件
capi-kubeadm-bootstrap-system:用于部署capi-kubeadm-bootstrap-controller-manager组件
capi-kubeadm-control-plane-system:用于部署capi-kubeadm-control-plane-controller-manager组件
capk-system:用于部署capk-controller-manager组件
查看这5个命名空间,会发现pod无法正常启动,原因是所有镜像都使用的官方镜像,导致无法正常拉取,修改下镜像源即可。
附录
手动部署cluster-api
在上面通过clusterctl init部署cluster-api的时候,其下载的源文件都在github上,存在下载失败的情况,此时就需要手动部署cluster-api了。
下载cluster-api相关的安装yaml,并执行安装:
# 步骤1:定义CAPI稳定版本(可根据需要修改,推荐和clusterctl版本匹配,此处以v1.5.3为例)
export CAPI_VERSION=v1.5.3
# 步骤2:下载cluster-api核心组件安装yaml(核心控制器、CRD等)
curl -L -o capi-core-components.yaml "https://github.com/kubernetes-sigs/cluster-api/releases/download/${CAPI_VERSION}/core-components.yaml"
# 步骤3:验证yaml文件是否下载成功(避免执行空文件)
if [ -f "capi-core-components.yaml" ]; then
echo "CAPI核心yaml下载成功,开始执行安装..."
# 步骤4:kubectl执行安装,部署到capi-system命名空间(CAPI默认命名空间)
kubectl apply -f capi-core-components.yaml
# 可选:验证安装结果,查看capi-system命名空间下的Pod是否正常运行
echo "验证CAPI核心组件运行状态:"
kubectl get pods -n capi-system
else
echo "错误:CAPI核心yaml下载失败,请检查网络或版本号是否正确"
exit 1
fi下载cluster-api-provider-kubevirt相关的安装yaml,并执行安装
# 步骤1:定义CAPK稳定版本(此处以v0.3.0为例,可前往官方仓库查看最新稳定版)
export CAPK_VERSION=v0.3.0
# 步骤2:下载cluster-api-provider-kubevirt安装yaml(CRD + 控制器)
curl -L -o capk-components.yaml "https://github.com/kubernetes-sigs/cluster-api-provider-kubevirt/releases/download/${CAPK_VERSION}/infrastructure-components.yaml"
# 步骤3:验证yaml文件是否下载成功
if [ -f "capk-components.yaml" ]; then
echo "CAPK组件yaml下载成功,开始执行安装..."
# 步骤4:kubectl执行安装,部署到capk-system命名空间(CAPK默认命名空间)
kubectl apply -f capk-components.yaml
# 可选:验证安装结果,查看capk-system命名空间下的Pod是否正常运行
echo "验证CAPK组件运行状态:"
kubectl get pods -n capk-system
else
echo "错误:CAPK组件yaml下载失败,请检查网络或版本号是否正确"
exit 1
ficluster-api-provider-kubevirt代码托管地址: kubernetes-sigs/cluster-api-provider-kubevirt: Cluster API Provider for KubeVirt (github.com)
cluster-api依赖的image
cluster-api安装所依赖的image:
# cluster-api依赖的镜像
registry.k8s.io/cluster-api/kubeadm-bootstrap-controller:v1.7.4
registry.k8s.io/cluster-api/cluster-api-controller:v1.7.4
registry.k8s.io/cluster-api/kubeadm-bootstrap-controller:v1.7.4
registry.k8s.io/cluster-api/kubeadm-control-plane-controller:v1.7.4
# cluster-api-provider-kubevirt依赖的镜像
quay.io/capk/capk-manager:v0.1.9ClusterResourceSet资源对象
概述
Cluster API 创建的集群仅包含最基本的功能。例如,它们没有 Pod 到 Pod 网络所需的容器网络接口 (CNI),也没有动态持久卷配置所需的 StorageClass。当前用户必须手动将这些组件安装到他们创建的每一个集群中。
因此,Cluster API 引入了 ClusterResourceSet CRD,ClusterResourceSet Controller 会自动将用户在 ClusterResourceSet 中定义的一组资源配置应用到相应的集群中(通过 label selectors 根据标签选择集群),使得 Cluster API 创建的集群从一开始就为工作负载做好准备,而无需额外的用户干预。
使用
要使用 ClusterResourceSet 来安装资源,我们需要提供资源所需的 YAML 文件。Cilium 支持使用 Helm 的方式来安装,使用 helm template 命令在本地渲染出 YAML 资源文件:
helm repo add cilium https://helm.cilium.io
helm repo update
helm template cilium cilium/cilium --version 1.16.0 --namespace kube-system > cilium-1.16.0.yaml
将上面生成的cilium-1.16.0.yaml生成为一个configmap:
# clusterresourceset是一个命名空间级别的资源对象,所以需要创建在与用户集群相同的命名空间
kubectl create configmap cilium-crs-cm --from-file=cilium-1.12.5.yaml -n tenant1之后创建一个clusterresourceset类型的资源:
apiVersion: addons.cluster.x-k8s.io/v1beta1
kind: ClusterResourceSet
metadata:
name: cilium-crs
namespace: tenant1
spec:
clusterSelector:
matchLabels:
cni: cilium
resources:
- kind: ConfigMap
name: cilium-crs-cm
从上面的资源描述可以看到,其关联的一个集群需要带有cni=cilium的标签,所以我们将租户集群添加上该标签:
kubectl label cluster tanent1 cni=cilium此时,clusterresourceset就配置好了,理论上租户集群就开始自动安装cilium了。但在实际测试时,没有生效,原因暂时不明。
另外, 在创建集群时也可以直接为集群指定标签:
apiVersion: cluster.x-k8s.io/v1alpha4
kind: Cluster
metadata:
name: tenant1
namespace: tenant1
labels:
cni: cilium # 安装 Cilium
...附录
参考: 使用 ClusterResourceSet 为 Cluster API 集群自动安装 CNI 插件_clusterapi环境安装-CSDN博客
Cluster-API对接provider
cluster-api使用azure作为provider:使用Cluster API管理数百个Kubernetes集群 - 云云众生 (yylives.cc)
cluster-api使用vsphere作为provider:Kubernetes Cluster API With vSphere入门实践-腾讯云开发者社区-腾讯云 (tencent.com)
cluster-api使用docker作为provider:Cluster-API研究-CSDN博客
生产高可用kubeadm.yaml配置
使用如下指令生成部署配置文件:
kubeadm config print init-defaults --component-configs KubeletConfiguration --component-configs KubeProxyConfiguration > kubeadm.yaml修改配置如下:
# cat kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.0.180 # 当前master节点的ip
bindPort: 6443
nodeRegistration:
criSocket: /run/containerd/containerd.sock # 使用 containerd的Unix socket 地址
imagePullPolicy: IfNotPresent
name: k8s01 # master节点的主机名
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
extraArgs:
authorization-mode: Node,RBAC
default-not-ready-toleration-seconds: "120" # 节点notready后驱逐pod的时间,默认300
default-unreachable-toleration-seconds: "120" # 节点不可达后驱逐pod的时间,默认300
default-watch-cache-size: "1000" # 用于 List-Watch 的缓存池,默认100
delete-collection-workers: "10" # 用于提升 namesapce 清理速度,有利于多租户场景,默认1
max-mutating-requests-inflight: "1000" # 用于 write 请求的访问频率限制,默认值200
max-requests-inflight: "2000" # 用于 read 请求的访问频率限制,默认400
certSANs: # 添加其他master节点的相关信息
- k8s01
- k8s02
- k8s03
- 127.0.0.1
- localhost
- kubernetes
- kubernetes.default
- kubernetes.default.svc
- kubernetes.default.svc.cluster.local
- 192.168.0.180
- 192.168.0.41
- 192.168.0.241
- 192.168.0.100
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 镜像仓库地址,k8s.gcr.io在国内无法获取镜像
kind: ClusterConfiguration
kubernetesVersion: 1.22.0 # 指定kubernetes的安装版本
controlPlaneEndpoint: 192.168.0.100:6443 # 指定kube-apiserver的vip地址,也可以指定一个外部域名,该域名需要解析至该vip上
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12 # service的网段
podSubnet: 10.244.0.0/16 # pod的网段
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
cgroupDriver: systemd # 配置cgroup driver为systemd
cgroupsPerQOS: true
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 10s
fileCheckFrequency: 20s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 20s
imageGCHighThresholdPercent: 85
imageGCLowThresholdPercent: 80
imageMinimumGCAge: 2m0s
kind: KubeletConfiguration
logging: {}
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true # 证书自动更新
runtimeRequestTimeout: 2m0s
serializeImagePulls: false # 允许并行拉取镜像
shutdownGracePeriod: 30s
shutdownGracePeriodCriticalPods: 30s
staticPodPath: /etc/kubernetes/manifests
syncFrequency: 1m0s
volumeStatsAggPeriod: 1m0s
maxOpenFiles: 1000000
enableControllerAttachDetach: true
enableDebuggingHandlers: true
# 这里添加kube-reserved, system-reserved仅作参考,官方建议不要开启
enforceNodeAllocatable:
- pods
#- kube-reserved
#- system-reserved
evictionHard:
imagefs.available: 15%
memory.available: 1024Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
evictionPressureTransitionPeriod: 2m0s
#kubeReservedCgroup: /system.slice/kubelet.service
#kubeReserved:
# cpu: "1"
# memory: 2Gi
#systemReservedCgroup: /system.slice
# 官方不建议开启systemReserved,因为可能会带来某些不可控的系统关键进程的异常,这里列出仅作参考
#systemReserved:
# cpu: "1"
# memory: 2Gi
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
bindAddressHardFail: false
clientConnection:
acceptContentTypes: ""
burst: 0
contentType: ""
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
qps: 0
clusterCIDR: ""
configSyncPeriod: 0s
conntrack:
maxPerCore: null
min: null
tcpCloseWaitTimeout: null
tcpEstablishedTimeout: null
detectLocalMode: ""
enableProfiling: false
healthzBindAddress: ""
hostnameOverride: ""
iptables:
masqueradeAll: false
masqueradeBit: null
minSyncPeriod: 0s
syncPeriod: 0s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "ipvs" # kube-proxy的转发模式设置为ipvs
nodePortAddresses: null
oomScoreAdj: null
portRange: ""
showHiddenMetricsForVersion: ""
winkernel:
enableDSR: false
networkName: ""
sourceVip: ""创建集群:
kubeadm init --upload-certs --config kubeadm.yamlKubernetes集群维护
添加节点
添加worker节点
在master节点上执行如下指令:
# kubeadm token create --print-join-command
kubeadm join 100.65.0.30:6443 --token x9xebi.zj5ud751eb8m00bk --discovery-token-ca-cert-hash sha256:342120110867977035f63a75a540a5e358a4b7288623f841168183a6b29fcb00
将输出的结果在要添加为worker的节点上执行即可。
添加master节点
在现有master节点上执行如下命令获取certificate-key:
# kubeadm init phase upload-certs --upload-certs
I0126 15:39:09.983554 3061375 version.go:256] remote version is much newer: v1.32.1; falling back to: stable-1.28
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
d74c0737264779407727f83394229793562d0c0785e1e4dcd78e552c98ffd1ba之后通过执行添加woker节点的指令拿到token和discovery-token-ca-cert-hash:
# kubeadm token create --print-join-command
kubeadm join 100.65.0.30:6443 --token x9xebi.zj5ud751eb8m00bk --discovery-token-ca-cert-hash sha256:342120110867977035f63a75a540a5e358a4b7288623f841168183a6b29fcb00
然后通过以上得到的内容拼接出添加master的指令:
kubeadm join 100.65.0.30:6443 --token x9xebi.zj5ud751eb8m00bk --discovery-token-ca-cert-hash sha256:342120110867977035f63a75a540a5e358a4b7288623f841168183a6b29fcb00 --control-plane --certificate-key d74c0737264779407727f83394229793562d0c0785e1e4dcd78e552c98ffd1ba
然后在要添加为master的节点上执行即可。
删除节点
无论是master节点还是node节点,删除方式都是一样的。首先在现有master节点上将目标节点设置为不可调度,并排干节点:
kubectl drain yichang-10-200-4-22 --ignore-daemonsets之后删除节点:
kubectl delete node yichang-10-200-4-22在删除的节点上执行重置操作:
kubeadm reset -f